Archiving Locals Content

I subscribe to two channels on Locals, a creator funding platform that was bought by Rumble. Both of the people I subscribe to produce a lot of content, and there’s no way to consume all of it, especially with Local’s abysmal web interface. In the past, I’ve archived content from The Blaze. The Blaze had a well-designed frontend interface and easy to handle JSON response. This made it almost trivial to archive content. Locals renders most of their HTML on their servers. A considerable amount of scraping and parsing is required, in order to archive their content. I created a tool called arclocals; a Python application anyone should be able to use if they want to archive the content of people they subscribe to on Locals.
Using Arclocals
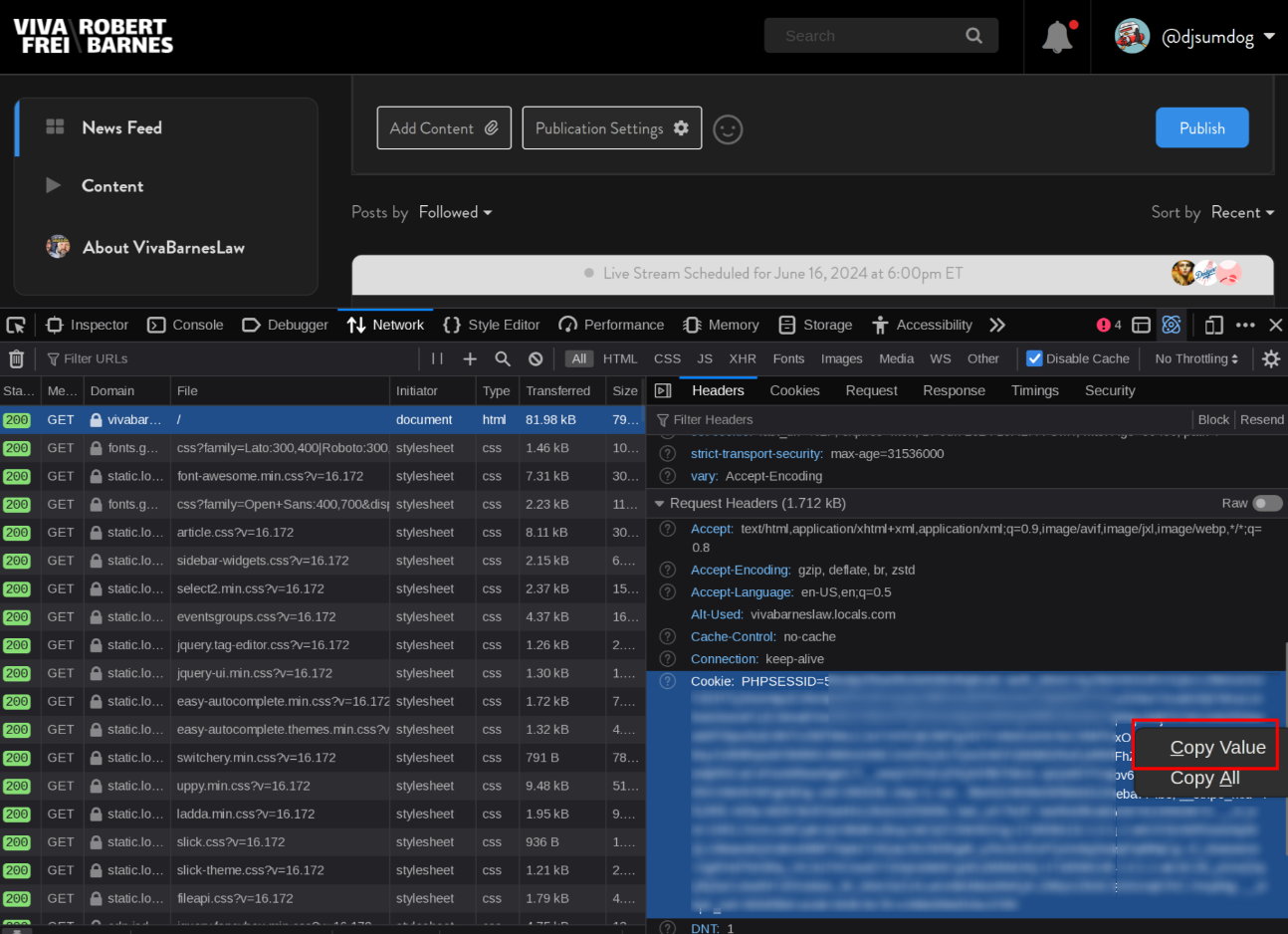
Be sure to check the project README, as it should have the latest information for installation, configuration and usage. From your web browser, you’ll need the Cookie header used on the Locals site you want to archive. Since all Local sites are on their own domain or subdomain, each subscription should have its own set of cookies. These cookies contain session and authentication tokens, as well as tokens for Cloudflare robot checks. So be sure to copy the entire thing. You can find it in the web browser network debugging console.
Installation
To install arclocals, you’ll need Python 3 and the Poetry build system. Poetry will download the rest of the dependencies. Simply clone the source code and initialize the project.
git clone https://gitlab.com/djsumdog/arclocals cd arclocals poetry install
Configuration
You must configure each Locals board you want to archive. Give them a name, and set the hostname and cookie string.
vivafrei: hostname: vivabarneslaw.locals.com cookie: "__stripe_mid=xx; cf_clearance=xx; PHPSESSID=xx; auth_token=xx; uid=00; stay=1; uuid=u_xxxx-xxx-xxxx; public_token=xxx; ...<get this from your web browser as shown in the screenshot above>" mugclub: hostname: mugclub.rumble.com cookie: "__stripe_mid=xx; cf_clearance=xx; PHPSESSID=xx; auth_token=xx; uid=00; stay=1; uuid=u_xxxx-xxx-xxxx; public_token=xxx; ...<get this from your web browser as shown in the screenshot above>"
Usage
There are two steps to archiving. First, you must grab all the metadata, and then run the download command in order to retrieve everything listed in the metadata. You can fetch a specific content type (videos, live, pdfs, podcasts or articles), or you can use the all type (the default)to grab everything. You can use --help to get all the commands and options.
# Fetch only video metadata for a site poetry run python3 -m arclocals --verbose mugclub fetch-metadata videos # Fetch all metadata for a site poetry run python3 -m arclocals --verbose vivafrei fetch-metadata all # Download all content for a site # (use --resume-fragments to retry previously incomplete downloads) poetry run python3 -m arclocal vivafrei download --resume-fragments
Issues
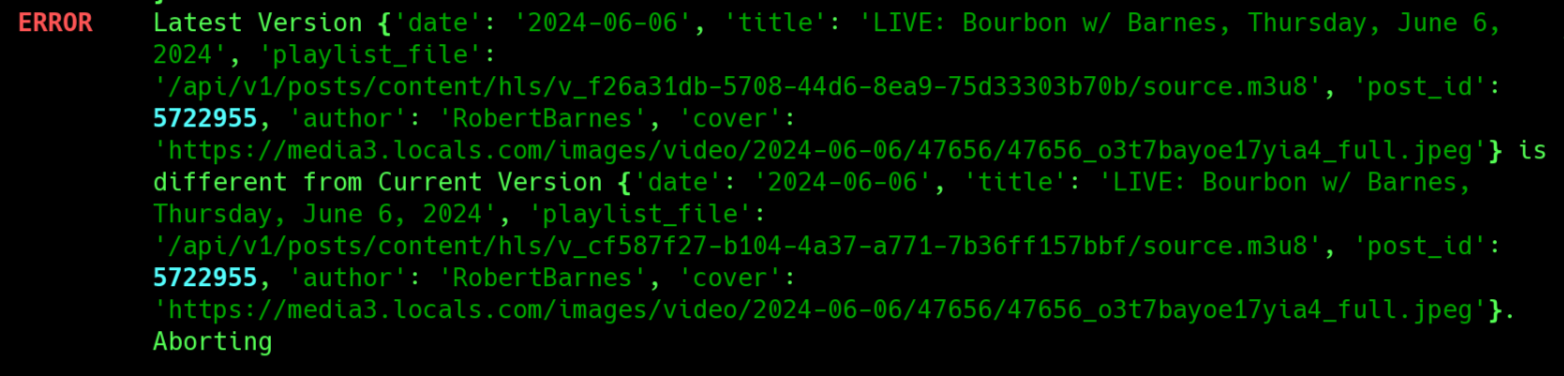
Each post on Locals has some property attributes that identify the author and a unique ID. If the information ever changes for a post, arclocals will produce an error and exit. This allows you to see any changes and adjust the metadata appropriately. Here is an example where a metadata update failed because of a title change.

In this particular case, I think the creator’s staff simply mislabeled some videos. The titles seem to have been swapped, but both videos were available. This could also show situations where creators intentionally change titles after publishing.
It also seems like live streams may have one URL while the account is streaming, and another one once the stream is finished and saved, as shown below. The metadata fetching doesn’t ignore active streams, so you may have to delete the older entry (and you might want to delete the video file too if you downloaded the live version, and would prefer the archived version).
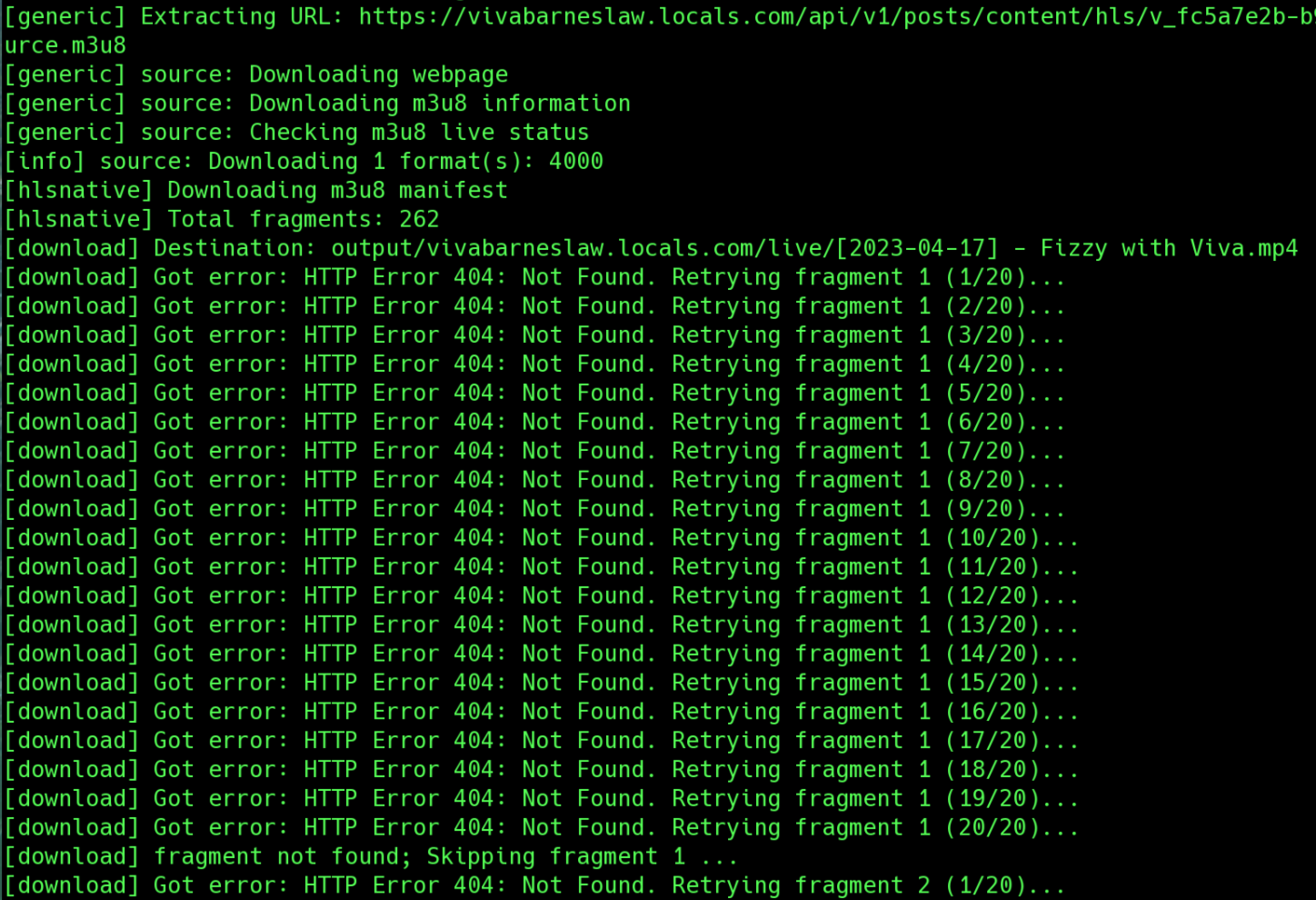
I found some content that simply didn’t exist at all. Under the surface, arclocals calls the yt-dlp Python library in order to download video content. I’ve found several cases where arclocals either couldn’t get the media URL, or couldn’t download any media fragments.
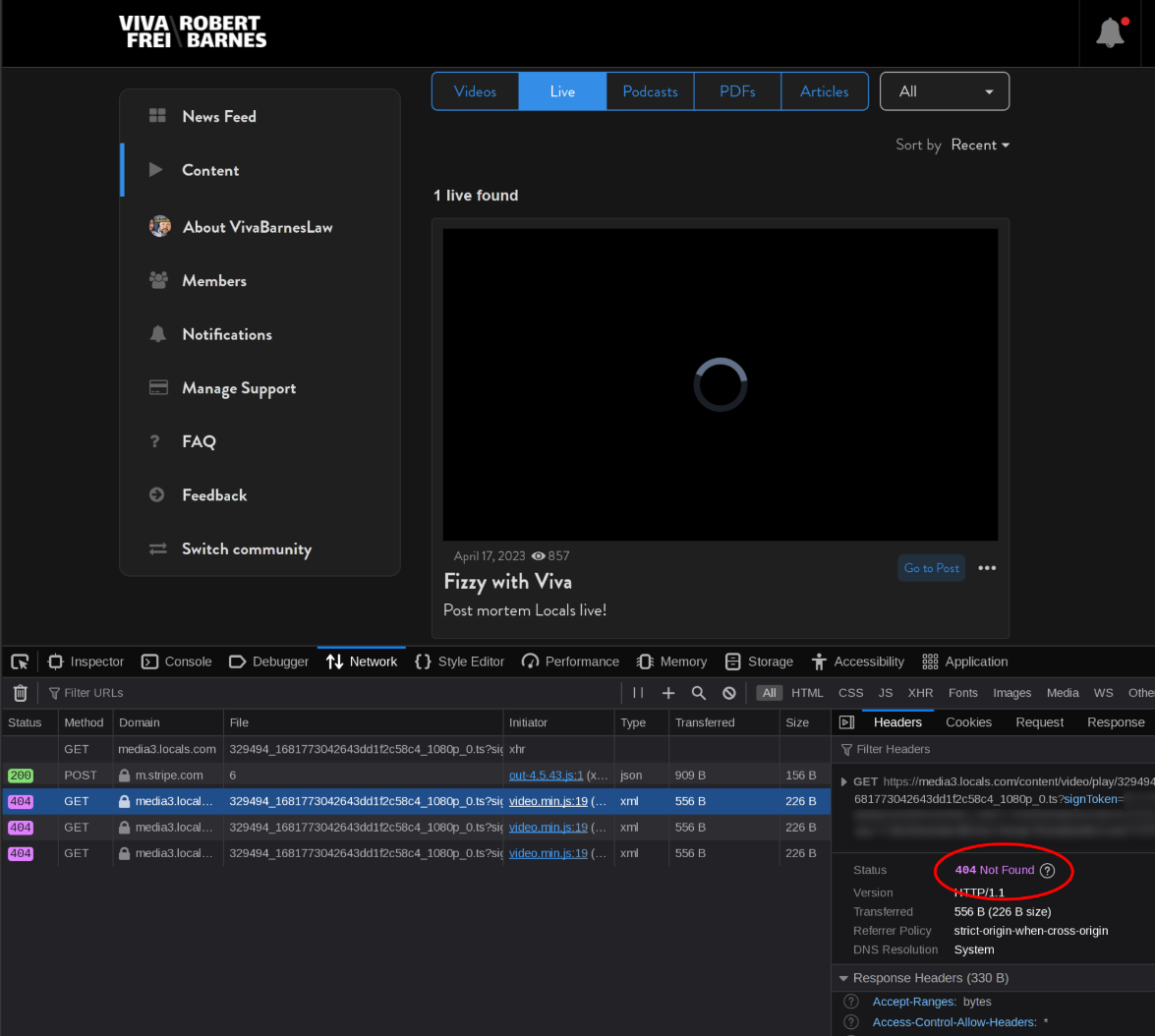
If I try to look up this content on the site, it doesn’t play and has the same issue in the browser.
Fragments
When using yt-dlp, I noticed a considerable amount of errors resulting in missing fragment files in my output directory.
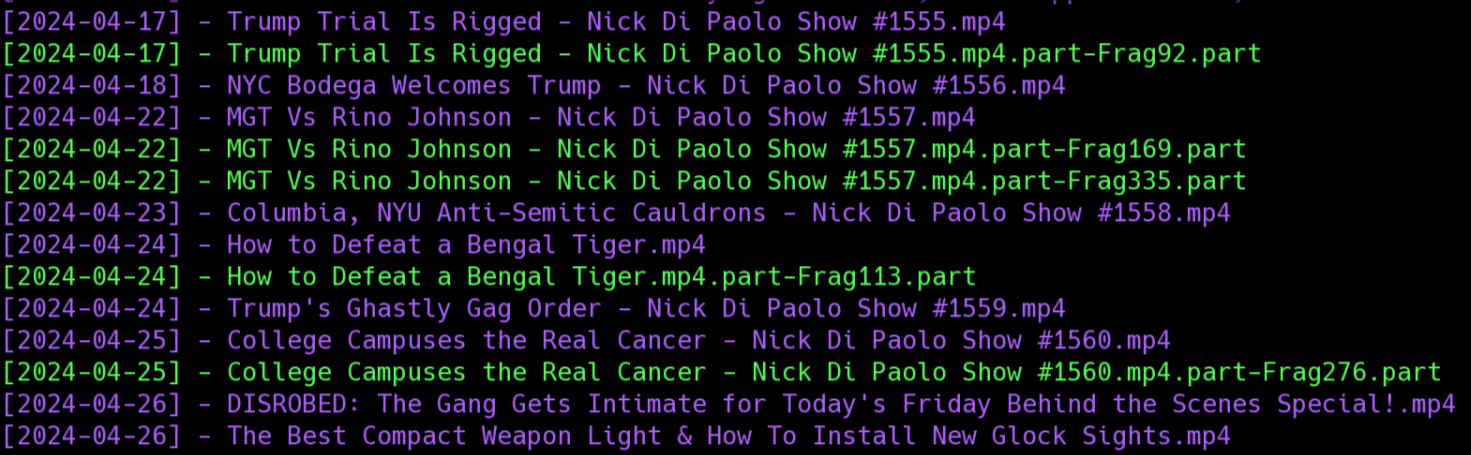
I attempted to move and redownload one of these files to see if the missing fragments were consistent. They were not. yt-dlp does have an option for retrying missing fragments1. I used the following fish shell commands to move the videos and fragments into a temporary folder:
mkdir ../bad-videos for p in *Frag*.part; mv (string replace -r '\.part-Frag.*\.part' '' "$p") ../bad-videos; end mv *.part ../bad-videos/
After verifying all the videos with fragment files were moved out of the way, I adjusted the yt-dlp options in download.py to include 'fragment_retries': 20. Twenty retries seemed like a more than adequate number. However, I still saw the timeout issues with no attempts to retry:
download] Destination: output/vivabarneslaw.locals.com/live/[2023-09-17] - Ep. 178.mp4 [download] Got error: HTTPSConnectionPool(host='media3.locals.com', port=443): Read timed out. [download] fragment not found; Skipping fragment 86 ... [download] Got error: HTTPSConnectionPool(host='media3.locals.com', port=443): Read timed out. [download] fragment not found; Skipping fragment 316 ... [download] 100% of 4.47GiB in 00:21:10 at 3.61MiB/s
The fragment_retries attribute is being used, but only if the fragment request returns a 404, not if it times out.
[download] fragment not found; Skipping fragment 277 ... [download] Got error: HTTP Error 404: Not Found. Retrying fragment 278 (1/20)... [download] Got error: HTTP Error 404: Not Found. Retrying fragment 278 (2/20)... ... ... [download] Got error: HTTP Error 404: Not Found. Retrying fragment 278 (18/20)... [download] Got error: HTTP Error 404: Not Found. Retrying fragment 278 (19/20)... [download] Got error: HTTP Error 404: Not Found. Retrying fragment 278 (20/20)...
I also ran into an issue where arclocals started downloading videos way too quickly, and I realized I was getting a bunch of short 30 second clips. I used the following command to deal with these by verifying and moving out everything under 100MB:
# Verify we're getting the right files
find . -name "*.mp4" -type f -size -100M -exec ls -lh {} \;
# Move them to a temporary folder.
# Some of these may be very short clips, so open them up
# and check if they're 30 seconds long
find . -name "*.mp4" -type f -size -100M -exec mv {} ../too-short/ \;
Refreshing the cookie in the configuration solved the 30 second clip download issue. I couldn’t figure out how to configure retries for the fragments in the underlying HTTP connection pool yt-dlp uses. Adding 'socket_timeout': 100 to the configuration helped some fragments complete. I added --retry-fragments as an option to download, which moves any downloads that also have fragment files into a directory named fragment-<unixtimestamp>. Each download seemed to fail on different fragments, so it’s likely the entire video is present. Local’s content server just has occasional timeout issues. Running download multiple times with --retry-fragments should eventually retrieve all the videos completely.
poetry run python3 -m arclocals vivafrei download --retry-fragment
Development
The project contains the Python library har2requests. You can run poetry shell and then har2requests on a HAR file to see the equivalent code needed for the Python requests library to make the same call. This tool was incredibly valuable in making calls that look like they came directly from the browser. It helped with debugging potential authorization, header and redirect issues. If you look at the code in arclocals/http.py, you’ll see where I initialize a session to look like my web browser.
def initialize_session(hostname: str):
session = requests.Session()
session.headers.update(
{
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:125.0) Gecko/20100101 LibreWolf/125.0.3-1",
"Accept-Language": "en-US,en;q=0.5",
"Accept-Encoding": "gzip, deflate, br",
"Referer": f"https://{hostname}/",
"DNT": "1",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Pragma": "no-cache",
"Cache-Control": "no-cache",
}
)
return session
HAR files can be downloaded from your web browser’s network debugging console. They contain a detailed replay of your browser’s network requests.
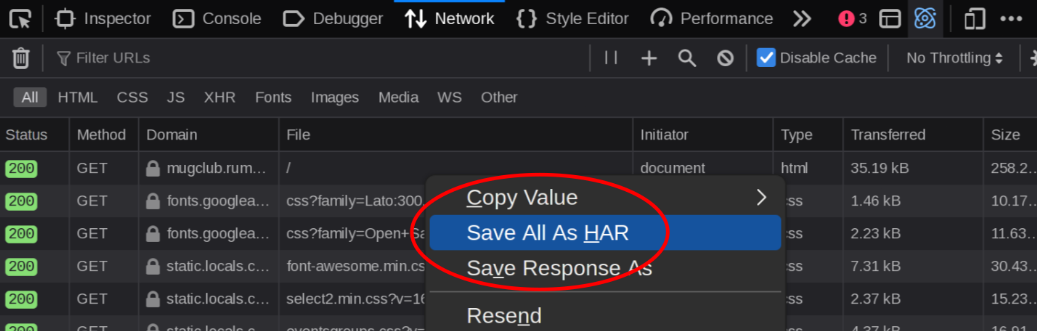
I didn’t make the User-Agent configurable. I may do so in the future, but you might need to adjust this in code to match the web browser you used to get your session cookie. Needless to say, arclocals is not for the faint of heart. If you’re going to use it, be prepared to get dirty with the code. arclocals relies heavily on the HTML (see arclocals/scraper.py) and could break if Locals makes web interface changes.
Issues with Locals
Locals originally pushed every creator’s community to be on their own subdomain (e.g. vivabarnes.locals.com). Now they are pushing everyone into their unified interface (e.g. locals.com/vivabarneslaw). If you want to get to the original interface, you have to go to a specific post and click on the little link icon in order to be directed back to the creators Locals board. If you look carefully, you’ll see this link has legacy in the URL that performs the redirect.
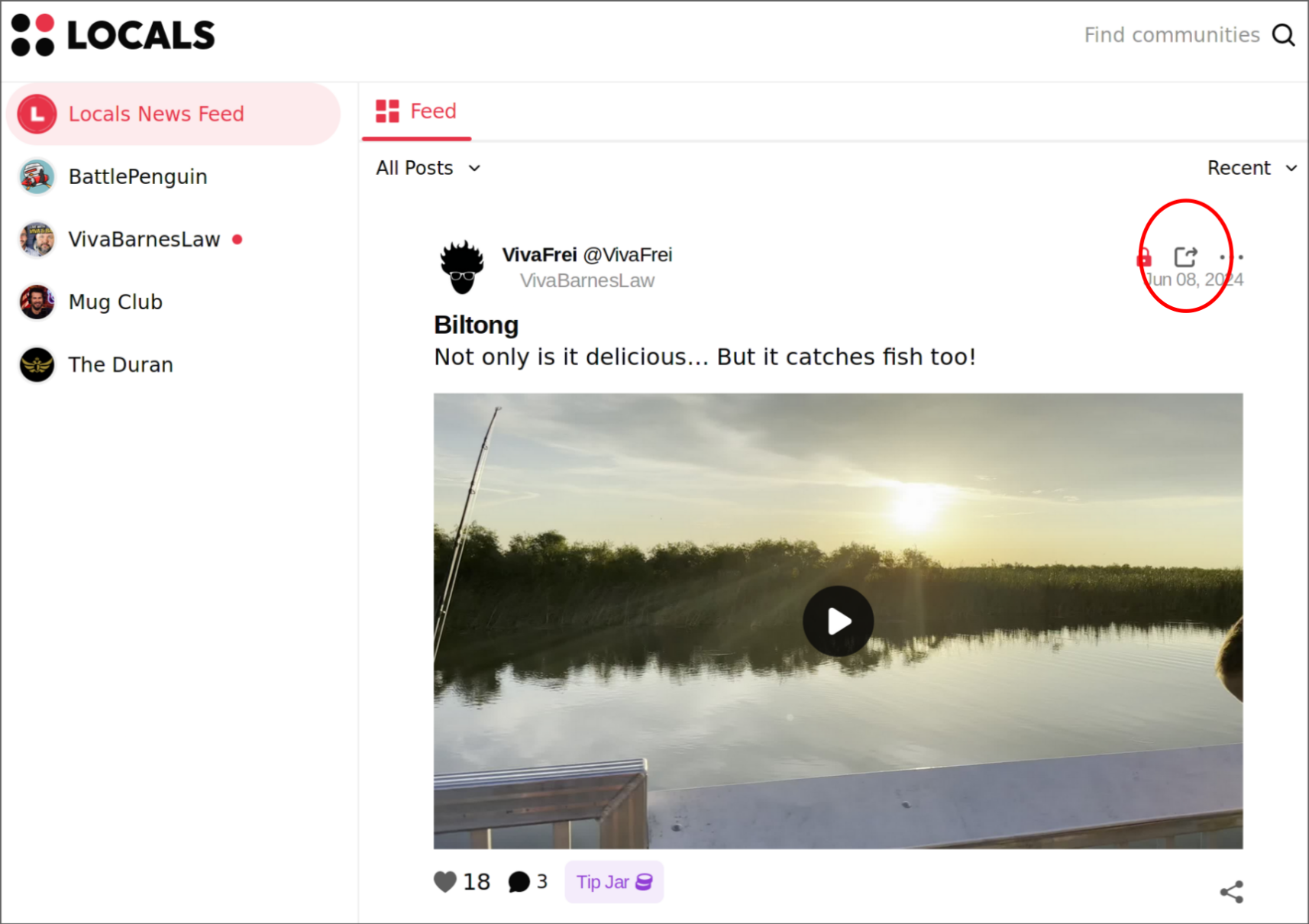
The old board web application is very poorly engineered. Since I use LibreWolf as my web browser (a privacy-aware fork of Firefox), Locals doesn’t properly identify it and constantly gives me their annoying mobile web browser popup asking me to download their mobile application. No matter how many times you decide to continue in the browser, this will keep popping up. I have no idea what their mobile application is like, but I assume it’s equally terrible as their web interface.
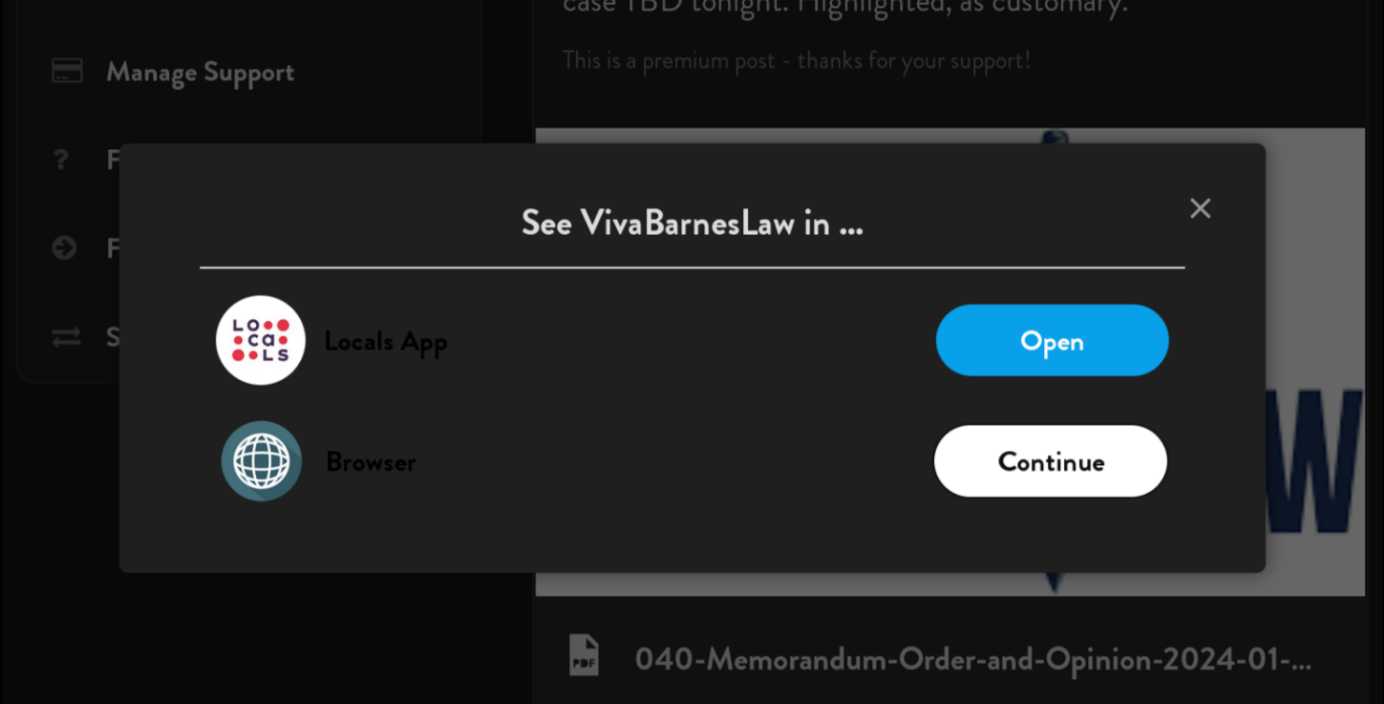
Locals claims to be a platform that fights against censorship, yet it uses Cloudflare, a company known for horrific censorship practices that border on outright defamation. Using their site gives me little faith in their content philosophy or the technical abilities of their engineers.
Why Archive?
Why go through all this trouble to archive content? In my particular case, there are some creators I have followed for years, and I’ve decided to end my subscriptions. I’ll cover my reasons for doing so in a future post. There’s a lot of old content I never got around to watching, and there’s a lot of it I probably will never watch. Still, it’s sometimes fun to go into the archives and skip through bits and pieces of what these people covered on their streams in previous years.
James Corbett sells yearly archives of all his content on USB sticks2, even though all of his content is free and none of it is pay-walled. It’s partially to show support for his reporting, but also so people can purchase real physical media archives of his videos and articles. So much of the Internet from the early 90s and 2000s has disappeared. Some content can be found on various archive sites, but if pay-walled subscriber content is taken down, it could be gone forever or become exceedingly rare.
I’m sure people my age and older remember friends who had massive walls or shelves filled with VHS tapes or DVDs of their favorite movies. People used to have physical media they could sell and trade secondhand. Today, people rely too heavily on streaming services, thinking the shows and movies they enjoy will simply be there forever as long as they pay a monthly subscription.
Archiving content, especially subscriber content for people who cover current events, can provide valuable insights into different viewpoints of a given era, long after the streaming and hosting services disappear. The search engines of the 2000s provided a vast landscape of information from all manner of writers and developers. Today, all search engines limit results, favoring major websites and squeezing out the tiny bits of content that made the early Internet so interesting. There are likely richer, vaster and more interesting archives of information in the hands of data hoarders than can be accessed by any major search engine.
-
Is there an option to throw away and re-get bad packets in yt-dlp? (comment). 24 May 2023. u/Empyrealist. r/youtubedl. Reddit. ↩
-
Corbett Report 2015 Data Archive (USB Flash Drive) – New World Next Week. New World Next Week Store. Retrieved on 8 June 2024. Archive ↩