Bibliobunny: A Tool for Extracting eBook Highlights From Kindle and Play Books

I like to keep backups of things other people just leave “in the cloud,” (which is really just some private corporation’s computer). In the past, I’ve used eReader software on tablets or phones. I wanted to create a book quote bot that would post random highlights from novels I’ve read. In order to do so, I first had to write tools to convert book highlights into usable formats. Bibliobunny is a Python application I wrote to parse notes from Amazon Kindle and Google Play note formats into JSON. It can also load those JSON files into a sqlite database, which can be used to post book quotes to a Pleroma server.
Setup
The configuration procedure may change in the future, so be sure to check the Bibliobunny project README before starting. As of right now, you’ll need Python and the uv build environment tool to run Bibliobunny.
git clone https://gitlab.com/djsumdog/bibliobunny cd bibliobunny uv sync
Converting Google Play Book Highlights
Google provides a service for backuping up your data. Using this service, you can get a download that contains the path Takeout/Google Play Books/<book title>.html which contains notes in HTML format. Unfortunately, these notes are all truncated with ellipses tacked onto the end.
<div class="note-text"></div> <div class="last-modified-date">Last modified on 13 Feb 2019, 07:37:46 Central Time</div></div> <div class="note"><div class="book-text">" “I’m getting a medal for falling into a pressure hatch, sacrificing an arm and a leg to keep seven sailors ... "</div>
This renders the HTML export fairly limited in its usefulness. The HTML doesn’t even provide links to the location in the web version of Play Books. A full, non-truncated version of the highlights can be found in Google Drive (Takeout/Drive/Play Book Notes/<book title>.docx). If you copy the Play Books Notes directory into the project, Bibliobunny can parse these docx files using the following command:
uv run python -m bibliobunny load-play-notes Play\ Books\ Notes/Notes\ from*docx
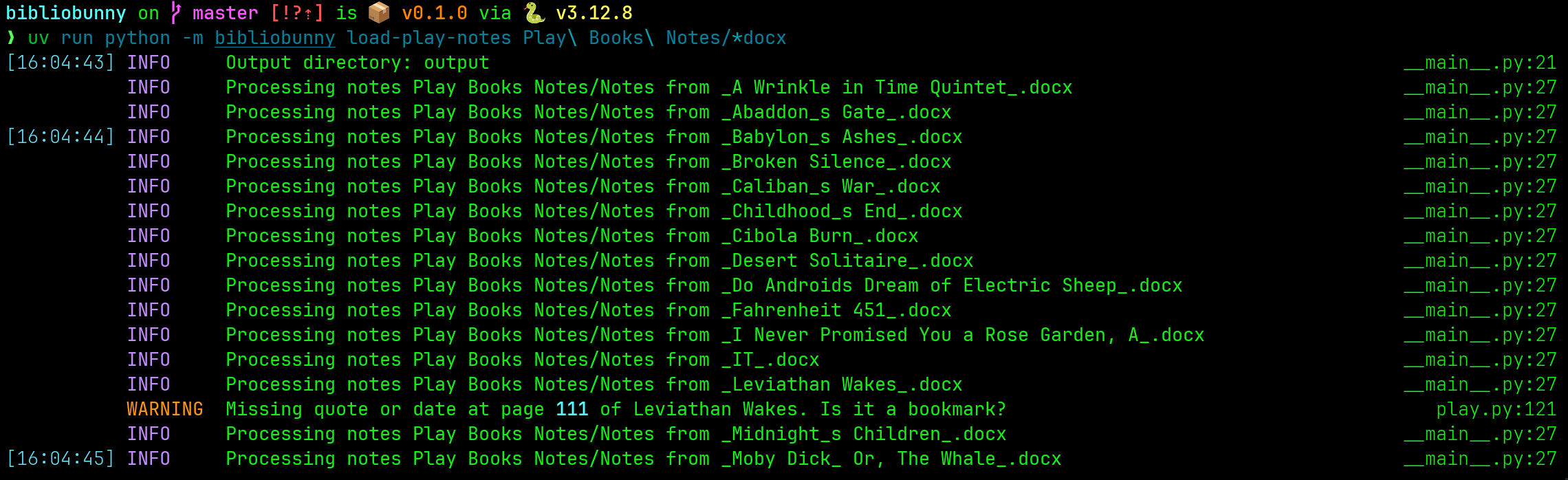
I used the python-docx library to parse each highlight file. Iterating over all elements in a document in order of appearance isn’t natively supported by python-docx, and required a special iteration function1. Unlike the HTML version, the docx version did have links that opened page numbers in Play Books. Unfortunately, the text from these links couldn’t be accounted for when attempting to iterate over each element type. I found a workaround using a patch to the text property of the Paragraph object, allowing it to unwrap and return the text from hyperlinks2.
The result is a set of JSON files that look like the following:
{
"title": "Moby Dick; Or, The Whale",
"author": "Herman Melville",
"publisher": null,
"notes_string": "108 notes/highlights",
"last_synced_string": "March 4, 2020",
"highlights": [
{
"quote": "If they but knew it, almost all men in their degree, some time or other, cherish very nearly the same feelings towards the ocean with me",
"notes": null,
"page": "15",
"date": "June 16, 2015",
"chapter": "CHAPTER 1. Loomings."
},
{
"quote": "Who ain't a slave? Tell me that.",
"notes": null,
"page": "18",
"date": "June 16, 2015",
"chapter": "CHAPTER 1. Loomings."
},
...
...
Converting Kindle Book Highlights
For Kindle books, I used the Android app to export highlights from all my Amazon books. When you have a book open, go into the annotations, then tap the sharing icon to export the notebook. Be sure to select None for the citation style. I’ve bought a total of 14 books through Amazon, and exported all the highlights manually via the app. If you have a large volume of books purchased via Kindle, this might be an encumbering process.
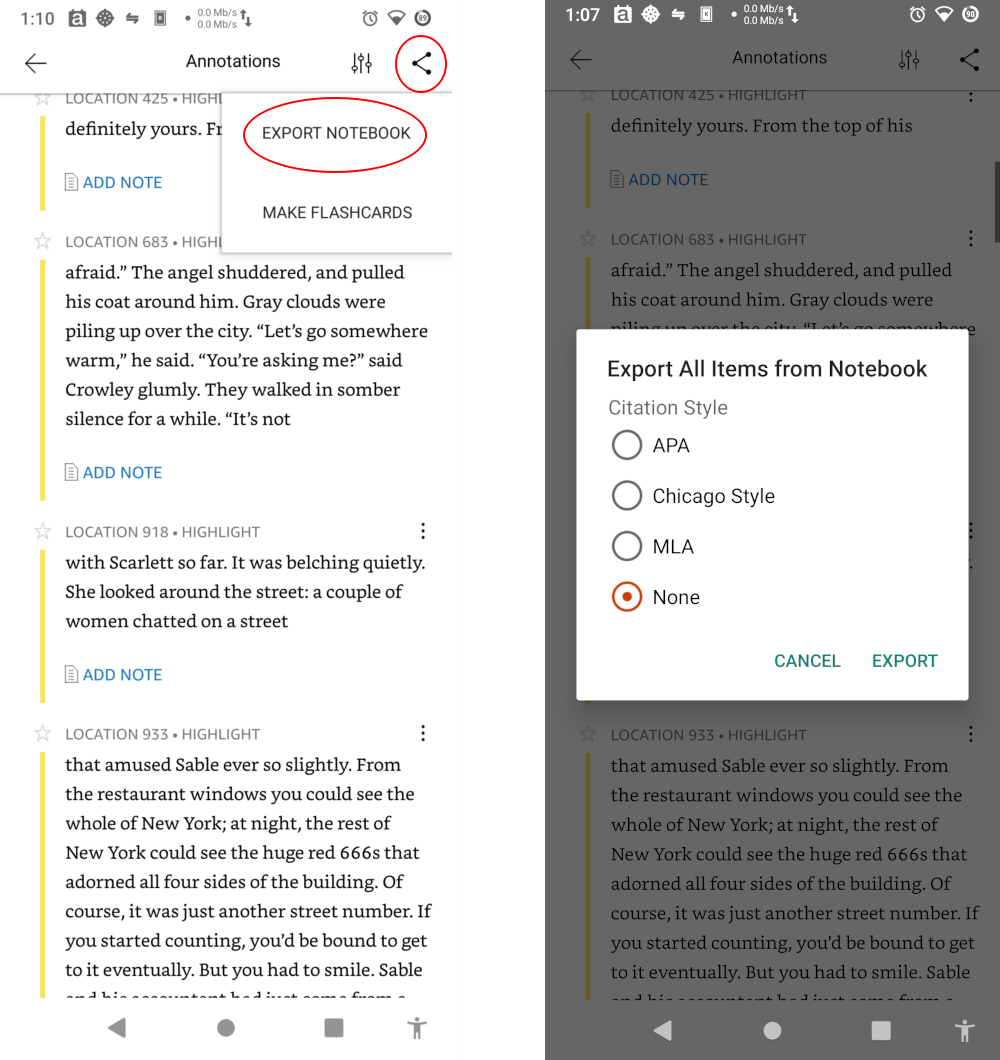
The highlight exports are all in HTML format, and it’s fairly well-structured with useful css class names and IDs. Bibliobunny uses Beautiful Soup 4 to parse the HTML and convert it to JSON. I placed these exports into kindle-book-note-exports and ran the following to convert:
uv run python -m bibliobunny load-kindle-notes kindle-book-note-exports/*html
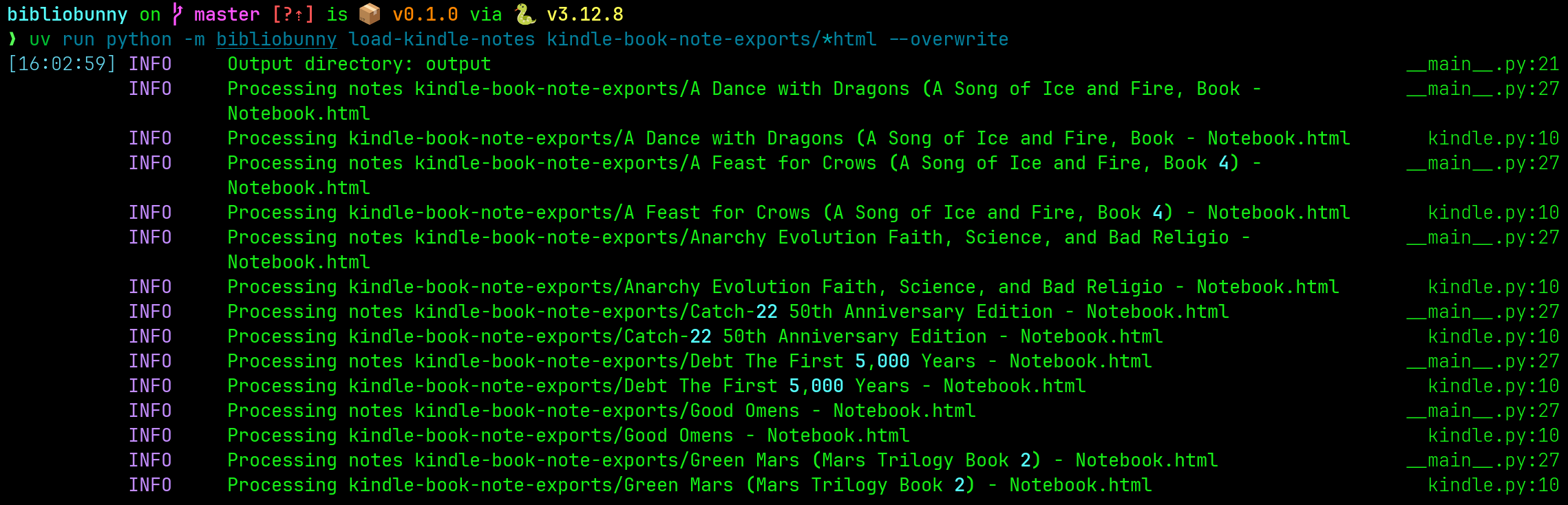
It produces similar JSON to what’s generated for Play Books. The page property for highlights may be an int value, indicating a page number, or the string Location appended with an int value for the Kindle location. The book metadata doesn’t include publisher, notes_string or last_synced_string.
{
"title": "Red Mars (Mars Trilogy Book 1)",
"author": "Robinson, Kim Stanley",
"publisher": null,
"notes_string": null,
"last_synced_string": null,
"highlights": [
{
"quote": "And indeed these men had the dangerous look that Frank associated with machismo, the look of men who oppressed their women so
cruelly that naturally the women struck back where they could, terrorizing sons who then terrorized wives who terrorized sons and so on and
so on, in an endless death spiral of twisted love and sex hatred. So that in that sense they were all madmen.",
"notes": null,
"page": "Page 9",
"chapter": "Part 1 - Festival Night"
},
{
"quote": "Defend a weak new neighbor to weaken the old powerful ones, as Machiavelli had said.",
"notes": null,
"page": "Page 10",
"chapter": "Part 1 - Festival Night"
},
...
...
JSON ➡ sqlite
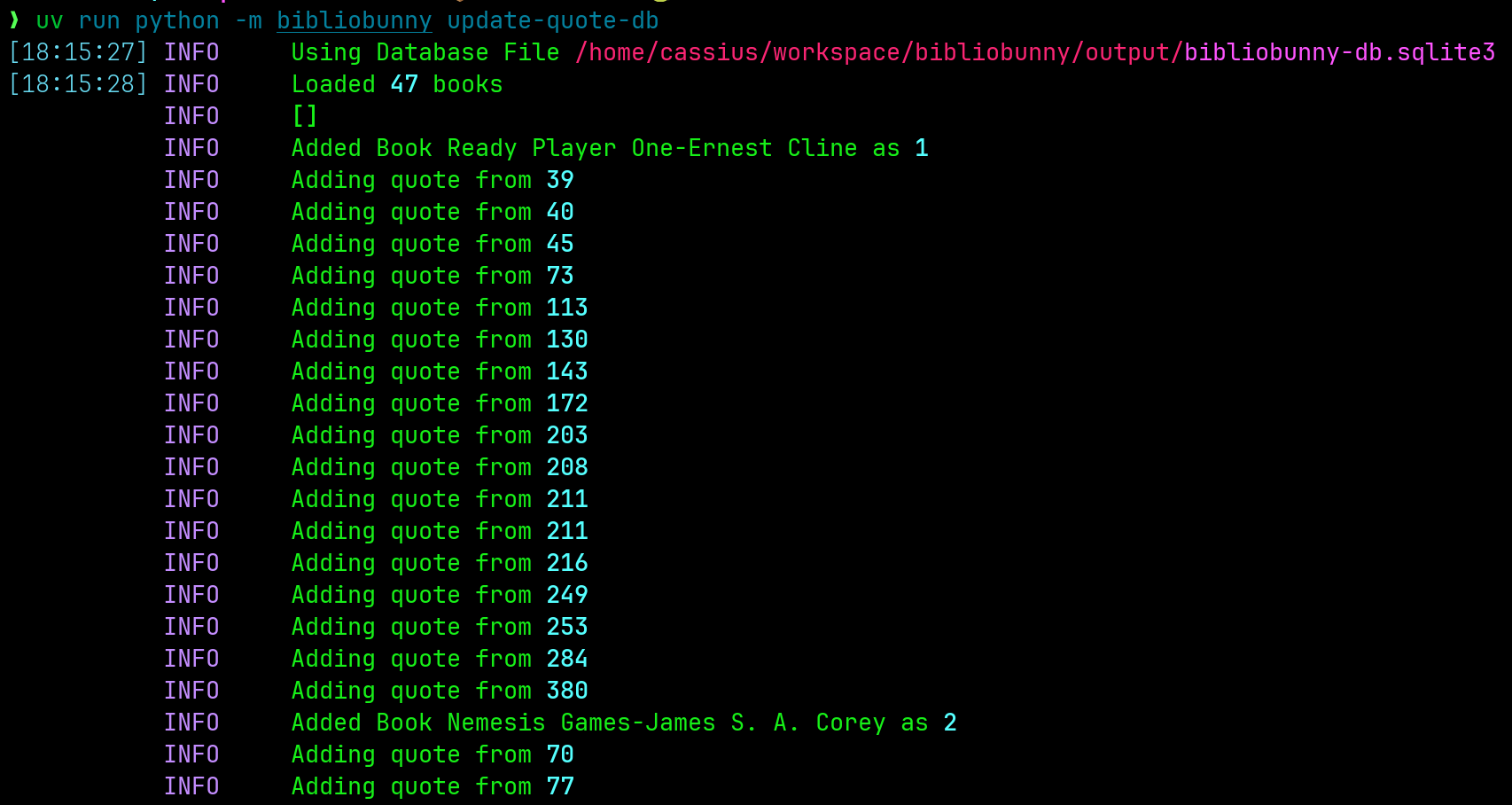
Bibliobunny also provides a posting bot. If you want to use these highlights with the bot, the JSON needs to be imported into a sqlite database. You might want to take a moment and review your highlights before importing them. Assuming your highlights are in the default output folder, you can load them into a sqlite using the update-quote-db command.
uv run python -m bibliobunny update-quote-db
Posting Bot
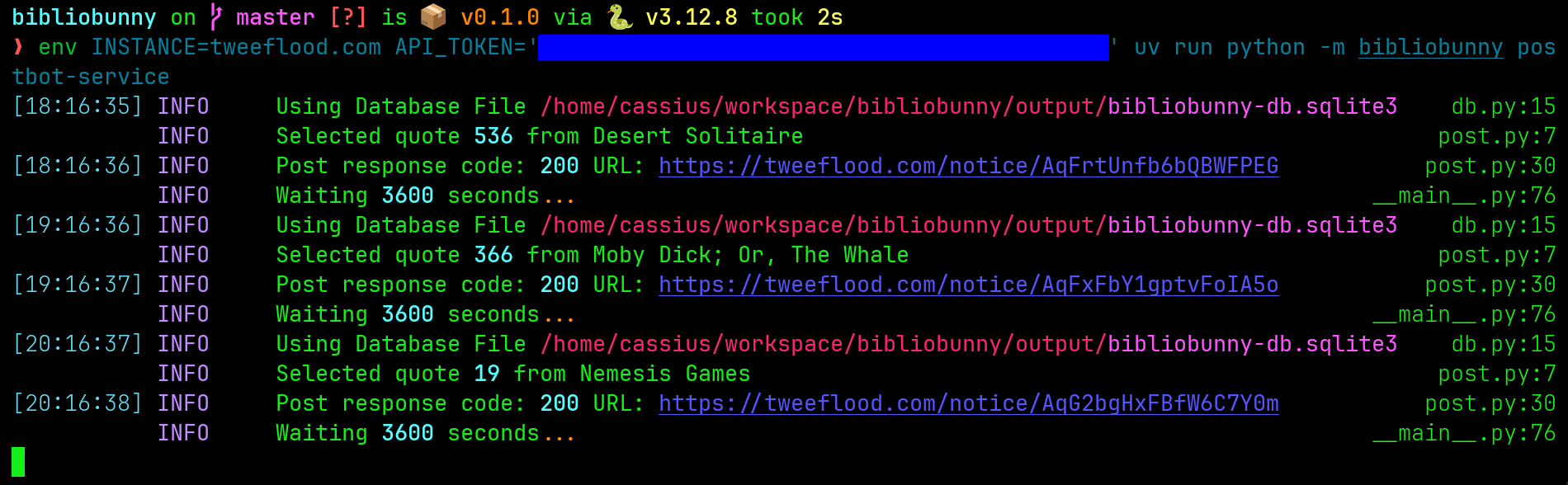
Bibliobunny can post random book highlights, at a set interval, to a Pleroma server. Mastodon currently isn’t supported as it doesn’t allow Markdown posts3, and posts have 500 character limits, making formatting difficult. By default, posts are made every hour. It tracks what quotes are posted to prevent repeats. The instance, api_token and interval parameters can be set via command line flags or environment variables.
env INSTANCE=example.com API_TOKEN='xxxxxx' uv run python -m bibliobunny postbot-service
Roadmap
As of writing this, I have a book quote bot you can follow at @bookquotebot@tweeflood.com from any Mastodon, Pleroma, Misskey, Pixelfed or other ActivityPub server. I’ve read books on some other apps and plan to add support for some additional readers. I wrote this because I wanted to make it easier to go through my book highlights and keep an archive of my own data. If you’re interested, checkout out the full project on the Bibliobunny git repository.
-
nested tables should be easy to handle with recursion. 20 November 2018. shulinwz. Github. ↩
-
feature: Paragraph.text includes hyperlink text #85. roydesbois. 10 September 2021. ↩
-
Add support for posting with Markdown syntax #23981. 6 March 2023. jessicarod7. mastodon/mastodon. ↩