Experimenting with Lazy Spec Driven Development
I’ve talked a bit about large language models (LLMs), and I do have friends who’ve been at odds with me for my reluctance to call these predictive algorithms “artificial intelligence”. Still, I do use LLMs frequently for coding both professionally and on my own projects. For things I care about, I often use them as a scalpel, either using chatbot output to implement my own design or heavily refactoring generated code to be maintainable. I’ve limited pure prompt-based development, or vibe coding, for simple one-time use tasks or throwaway scripts. Recently, I’ve started using LLMs for workflow projects using only lists of text specifications. In a radical departure from my normal engineering flow, I’ve let agents just write software without individually verifying the code. I do often get usable tools, although they often need a considerable number of refining steps. However, looking under the surface reveals confirmations of many of my apprehensions about heavy dependence on these tools for critical or production systems.
The Spec
I hesitate to call what I’ve done true spec-driven development. I’ve seen projects that embrace this practice create detailed documents defining languages, unit test creation and frameworks. They’ll treat the specifications as the source of truth, often using tools like Spec-Kit, and only allowing code updates via specification documents.
For my experimentation, I use a skeleton project with the base layout, libraries and tools I’ve come to use on other Python projects. I’ll add in an AGENT.md or CLAUDE.md that specifies all my coding conventions and suggested best practices. Then I create a specification of what I want to build, listing each requirement in as much detail as I can. I include database layouts, framework choices and specific details catering to how I would implement the project. I then tell a coding agent to read the base convention file and implement the spec.
After testing it out and making sure the base functionality works, I create a git commit with the spec in it. Usually I try to list all the bugs, issues or further improvements in a new spec. Small changes I might just ask in the existing prompt before committing, so the entire project may not be entirely reproducible using just the committed specs. If it’s something as small as a style sheet or visual change, I might just find the code myself so I’m not wasting tokens or compute power on something as stupid as changing margins on a box or the size of an icon.
If I use a new context window, I may simply tell the LLM to load AGENT.md, tell it that specs 01 - 05 have already been implemented by previous sessions, and to implement spec 06. Although this approach may prevent the previous specs from being loaded into the current context window, I haven’t seen any noticeable regressions by running my agent this way.
Cosszy
Back when I was in college, I wrote Isszy, a simple image sorting program written in Java. Over the years, I’ve still used this program, with light modifications so it could also sort RAW images from my cameras. I haven’t updated the original release, as most of my modifications were kludged together for my specific photography workflows. I decided to see if I could get a full rewrite of this tool using an LLM and specs. The result is Cosszy, a web-based image and video sorter.
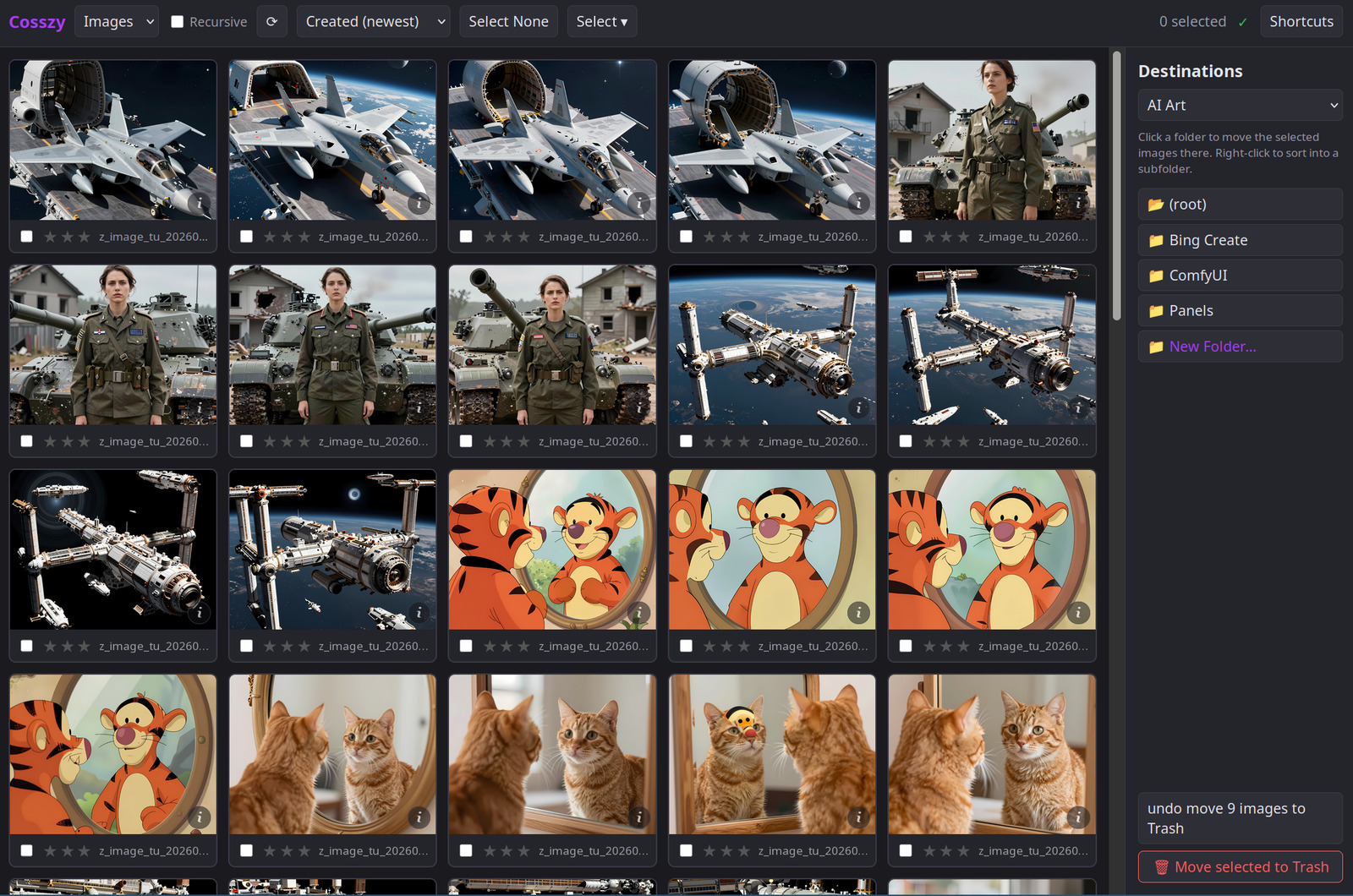
I was pretty surprised by just how well this application worked from the start. There were some bugs and UI issues, of course, but I mostly had the LLM fix them with further iterative specs. Still, the initial specs were very detailed with the exact technology, project layout, libraries and tooling I wanted the project to be based around. It used my current skeleton Python web project, which had a clean platform from which to build from.
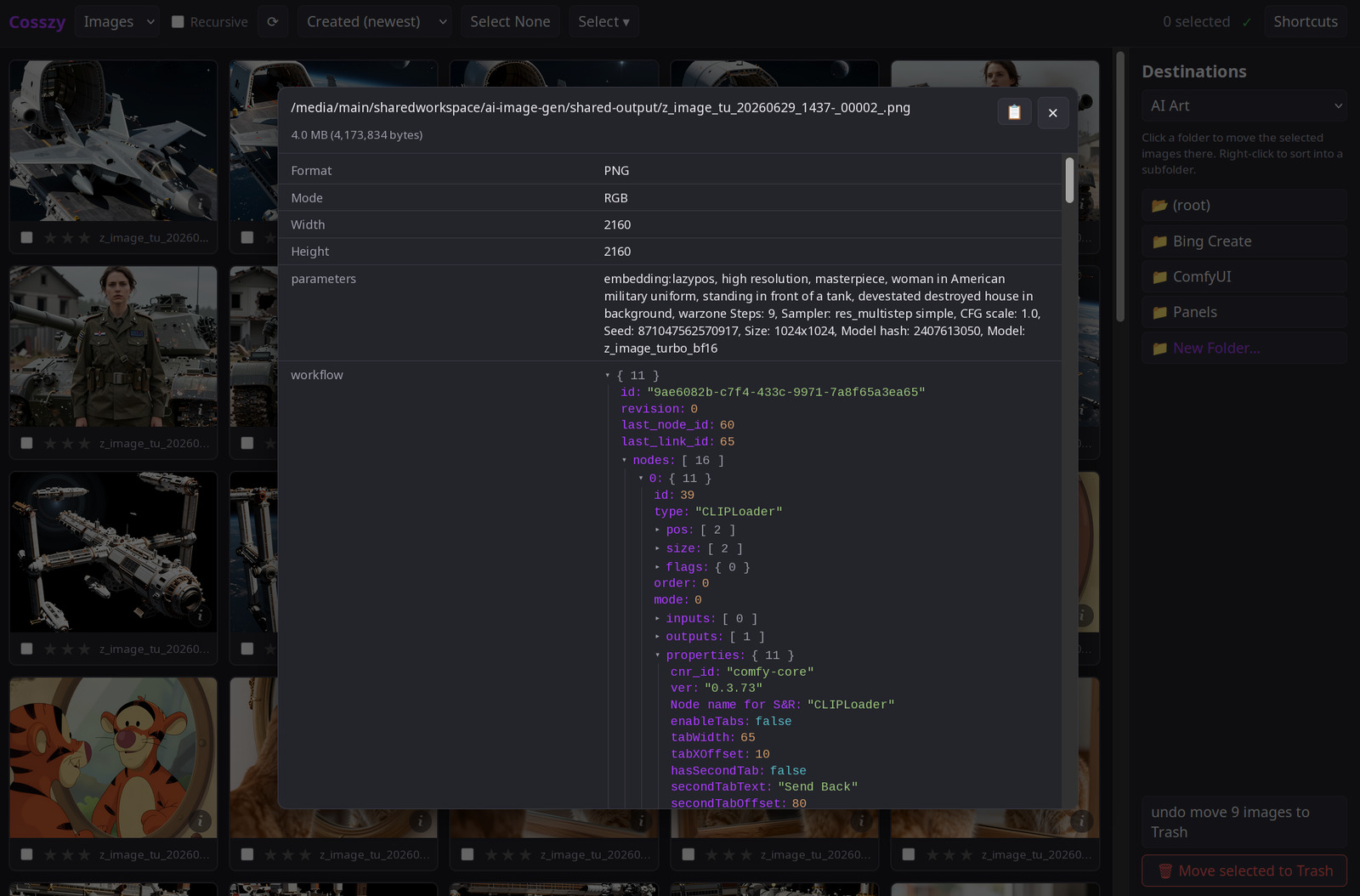
There were some interesting things the tool did that I didn’t specifically ask for, such as writing unit tests and a README file. Curious as to what would happen if a file with a duplicate name was moved to an existing folder, I discovered the LLM had implemented a process where the file gets an _1 appended to its name without any user intervention or indication. I then used a spec to implement a full overwrite and rename dialog.
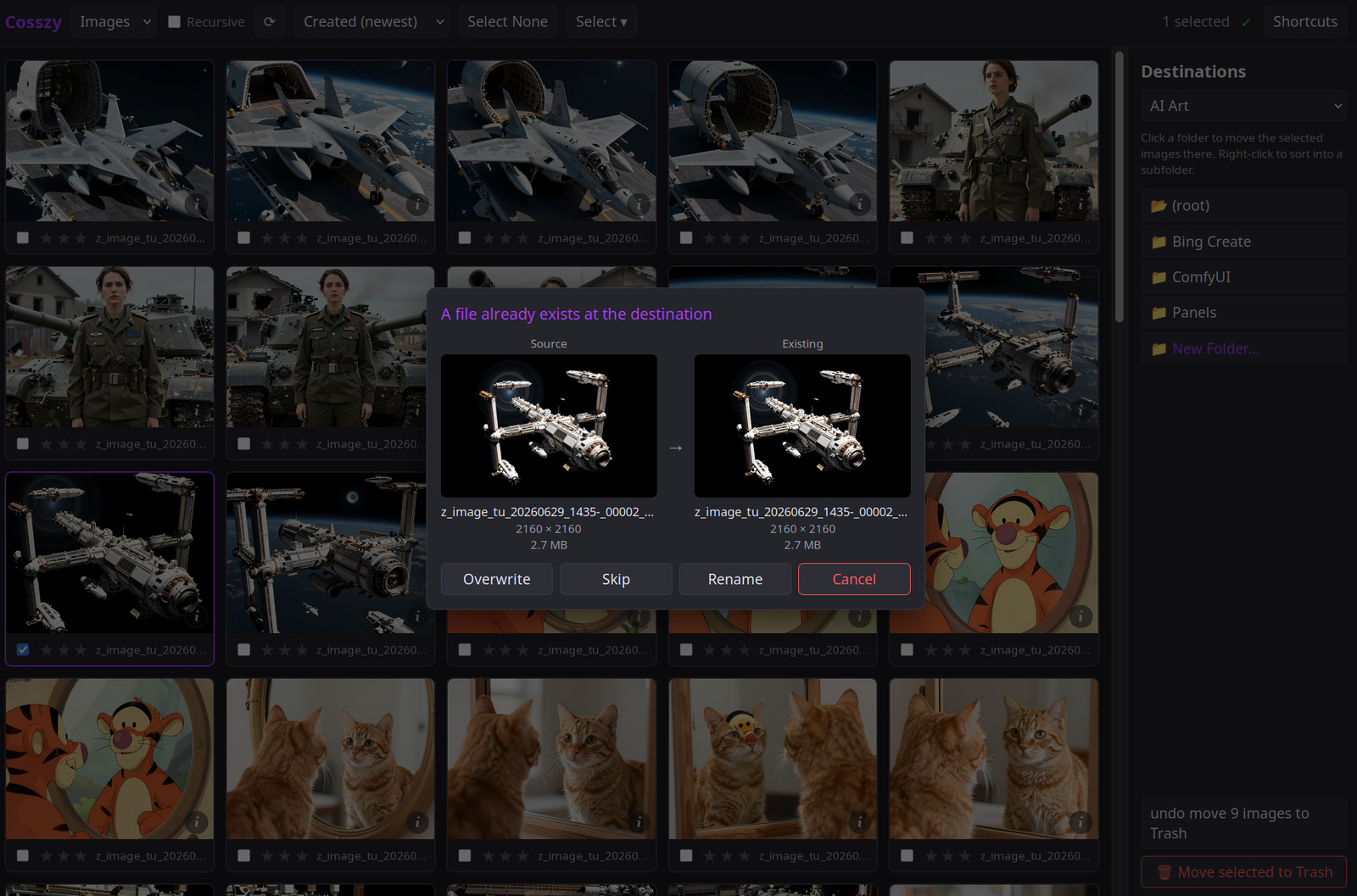
After several iterations, the program does work fairly well. I’ve only hand-tweaked a few issues that were easier to do myself or that the LLM would not fix correctly, mostly around visual positioning and style sheets. Parts of the underlying code are actually quite clean and fairly well organized, while other pieces have a lot of repeated elements and are a pile of spaghetti mess. It is something that anyone can run thanks to the included README, and works well as a part of my general workflow.
Comf-meta
ComfyUI is a tool used for image and video generation. It can send prompts to cloud providers, but I only use it to generate media on my own hardware using models I download and run locally. Comf-meta started off as a tool I created for extracting metadata from generated images to help me organize media and workflows. I used a skeleton project as a basis, but a lot of the commands were flushed out using prompt-based coding.
ComfyUI is honestly not that comfy. I found it more powerful than alternatives like AUTOMATIC1111, but working with it for any amount of time quickly leads to the realization most of the tool is likely AI developed. Looking up long-standing bugs and going through its issue tracker really makes this apparent.
I wanted to make a console or text user interface (TUI) for my ComfyUI workflows. I took several workflows for images and video I’ve found and refined, exported them (both UI and API JSON), and then tasked the LLM with converting them so the requests could be submitted in a console application that used the Textual and Rich libraries for Python.
Although I’ve posted the source code for Comf-meta, it’s heavily dependent on a customized Docker container built specifically for running ComfyUI on an AMD video card using ROCm. The workflows depend on a lot of custom nodes and assume the installation of specific models. At some point in the future, I might update it with a fully reproducible and distributable installation process. For now, it’s just a demo of a custom workflow I created using specs.
The Code
This approach focuses on the end result and forces me to not care about the code at all. When I do occasionally look at what the weighted code prediction machine has produced, some of it is surprisingly clean and well engineered. Some of it is repeated blocks. A lot of it uses function names and patterns I would never use. Most of these LLMs love to use blanket exception catching to hide issues that really should be errors. They tend to assume a lot of defaults as well, and generate things that are sometimes suboptimal or clearly wrong.
Using this approach is incredibly powerful for small local workflows, so long as they’re carefully tested along the way. However, I would be very hesitant to use anything like this for production grade applications or anything in a mission-critical environment.
This approach also requires a lot of understanding of all the underlying technology needed to implement the project. I specifically requested tools like Vite and Vue in my specs, as well as defining what tables and data structures I wanted. People without a software engineering background may simply get applications written in a generally popular software stack, such as Node and React. It could lead to a stagnation of newer technology adoption as the models will simply default to the technologies popular at the time they were trained.
Add GPLv3 Poison to Everything
I’ve previously licensed a fully generated project I used for fixing Sonatype’s license bait and switch as CC0 (public domain). Without writing any of the actual code, I considered licensing it as anything else to be dubious. However, I am concerned with just how much open-source code has been used to train these models. So far the court systems seem to be siding with the producers of LLMs1, while several lawsuits from publishers are still being litigated23. This is a pretty stark contrast to how the music industry convinced a college student to settle for $12,000, his life savings in 2003, for simply writing a search engine that happened to index music files45.
Large tech companies may claim to support open source, but they do not like the General Public License (GPL). Apple actively removed most GPL-licensed software from their operating system years ago. The GPL requires that when you release modified software to the public, the modified source code needs to be released as well. Big tech prefers licenses like MIT or Apache, which allow them to take existing open-source projects and integrate that code into their products without contributing those changes back to the community.
With Meta’s Llama 3.1-70B model being able to reproduce close approximations of nearly half of Harry Potter and the Sorcerer’s Stone67, I’m not convinced recent court cases are going to hold long term in regards to LLM-generated output and copyright. A higher court decision could radically shift the rules around products with generated content. Still, for now, I think it’s important to release all generated code under version 3 of the GNU Affero General Public License (AGPLv3). If another developer gets the LLM to generate the exact same code, yet it is already published as AGPLv3, does the generated code become AGPLv3 as well? It’s an interesting legal question, and adding an AGPLv3 license to every generated project ensures that question will have to be addressed eventually.
Cognitive Decline
There is considerable evidence to suggest using LLMs reduces our cognitive abilities when it comes to research, especially after returning to human or search engine-based research after prolonged exposure to LLMs8. Heavy use of chatbots can also lead to delusional spiraling9, and there are a seemingly endless number of studies coming out showing how these tools can lead to AI psychosis and cognitive issues10.
I find these studies compelling, and I’ve found that it’s easy to get disconnected from software engineering when using a lot of these tools in the manner I’ve described so far. I do think that it negatively affects my engineering abilities. However, I can’t deny the fact that they’ve helped me make tooling I’ve put off for weeks or months, some that I may have never started at all. For local workflows, homelabs and small, specific tasks, they’re incredibly useful. Yet they also require a considerable amount of “handcrafted” design and programming experience in order to tell the machine specifically what needs to be generated and avoid getting totally unusable output.
Owning Your Tools
I also hate that the models needed to perform these tasks require cloud services. As someone who self-hosts nearly everything, including my own chat services, social media, text message gateway and even e-mail, I really do not like using a paid or cloud service for critical software work. Although local models are getting better and some can work on consumer hardware, they still don’t quite compare to the large and computationally expensive models designed by Anthropic and others.
Anthropic the Drug Dealer
Anthropic has also been notorious for baiting and switching their customers. In May, they tried to disguise moving some Claude usage over to API billing as ‘free credits,’ hiding a potential 25x price hike1112. They’ve also been found offering different features and pricing selectively on their product page in order to determine how much potential customers were willing to pay for their services1314; a type of targeted pricing that’s also been happening with Instacart in the retail space as well151617.
Recently, Anthropic announced policy changes starting on July 8th, stating they could ask for government ID and facial scans in order to maintain access to their platform for all free, pro and max subscribers (business and enterprise customers are exempt)18. As someone who doesn’t even allow restaurants and music venues to scan my ID, there’s no way in hell I’m ever uploading my ID or facial biometrics to Antrhopic. We might see a rise in purchasing tokens from grey or black market transit stations (which might be fraudulent and stealing all your chat session data19).
It’s not clear if this policy will be selective or apply to everyone. I do think there are a lot of software engineers who, despite privacy concerns, will gladly give over their government ID and biometrics in order to either maintain access to Opus or gain access to Anthropic’s mythical fable of a model. There are people who have become so dependent on this technology that writing software by hand again would seriously lead to withdrawal and require weeks to rebuild lost cognitive skills.
Final Thoughts
I have a good friend, a fellow software engineer, who I’ve known and have kept up with since graduating university over 20 years ago. He’s very “bullish” on AI and has told me I should engage with LLMs more while coding, while also challenging many of the concerns I’ve brought up over data centers, sustainability, the growing cost of personal consumer hardware and the potential decline of our own cognitive abilities.
This article’s original intent was to document my experiences experimenting with specification and agent-based coding, without paying attention to the generated output. However, the acceleration of events in the LLM industry in just the past few weeks has also pushed me to elaborate more on my concerns as to where we are headed with these new tools.
The projects mentioned here, as well as others I’ve driven using specification documents, both at home and at work, are limited to non-critical workflows with very specific requirements. They are amazingly powerful and have saved me a considerable amount of time, but they also don’t feel like they’re mine at all. I don’t feel like I have personal ownership of these programs. Although I post their git repositories publicly under my own account, I don’t think I would ever package and distribute them. They still feel like an open-source program I found and ran, or a piece of software I commissioned a contractor to write, rather than something I created myself.
I’m sure at some point I will lose access to these frontier models, most likely due to an unwillingness to submit government ID. I’m okay with having to return to using a shovel instead of a backhoe to dig out a trench. Unlike an LLM, using a backhoe doesn’t atrophy one’s cognitive ability. I may also look at open coding models again because owning your own tools is far better than having to rent those tools from people with acceptable use policies that could ban your ability to rent those tools forever.
I am greatly concerned about the future, not just of software engineering, but many of the other professional fields that LLMs are being shoved into where they don’t really fit. The danger of AI is not what’s presented in the movies: a killer super-intelligence that decides to either enslave or end humanity. The real dangers are the people who become dependent on these machines, thinking they’re some kind of authoritative source, oracle or god, when in reality they’re just very good next-word prediction algorithms. Sometimes they are magically impressive, which makes us forget or dismiss the other times when they string together the wrong set of tokens, telling us to eat rocks, use glue as a pizza ingredient, or dismiss our own cognitive abilities in favor of the weighted word generator.
-
Meta Wins Blockbuster AI Copyright Case—but There’s a Catch. 25 June 2025. Knibbs. Wired. ↩
-
HW News - 12VHPWR vs 5090, Cyberpower Responds to GN, AMD RX 9070, Meta’s Piracy, & 5060 Ti. 16 Feburary 2025. Gamers Nexus. ↩
-
Kadrey, et. al. vs Meta Platforms Case 3:23-cv-03417-VC - Document 598. 25 June 2025. ↩
-
RIAA Grabs Student’s Life’s Savings. 10 June 2003. CowboyNeal. Slashdot. ↩
-
RIAA Wrath Hits Teen. 9 June 2003. Martell, Tech Live. ABC News. (Archived) ↩
-
Study: Meta AI model can reproduce almost half of Harry Potter book. 20 June 2025. Lee. Ars Technica. ↩
-
Extracting memorized pieces of (copyrighted) books from open-weight language models. 1 May 2026. Cooper, Lemley, Casasola, et. al. Computation and Language (cs.CL). ↩
-
Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task. 10 June, 2025. Kosmyna. Hauptmann. Yuan. et. al. MIT Media Lab. arXiv:2506.08872. ↩
-
Sycophantic Chatbots Cause Delusional Spiraling, Even in Ideal Bayesians. 22 Feburary 2026. Chandra. Kleiman-Weiner. Ragan-Kelley. et. al. Computer Science: Artificial Intelligence. ↩
-
We’re Already Living in an Alien Invasion Movie. 17 June 2026. Truthstream Media. (15m:20s) ↩
-
I need to rant, Anthropic is worse than my high school’s drug dealer. 16 June 2026. Louis Rossmann. ↩
-
Claude’s ‘Free Credits’ Hide 25x Price Hike. 13 May 2026. Clawd.rip. ↩
-
Louis loses mind on Anthropic speedrun towards enshittification. 29 April 2026. Louis Rossmann. ↩
-
For clarity, we’re running a small test on ~2% of new prosumer signups. Existing Pro and Max subscribers aren’t affected.. 21 April 2026. @TheAmolAvasare. X. ↩
-
Same Cart, Different Price: Instacart’s Price Experiments Cost Families at Checkout. 9 December 2025. Groundwork Collaborative. ↩
-
Same Product, Same Store, but on Instacart, Prices Might Differ. 9 December 2025. Casselman. The New York Times. ↩
-
Who Wants to Live in This Digital Prison. 26 June 2026. Truthstream Media. ↩
-
Claude Identity Verification Starts July 8: What Facial Data Anthropic Collects. 21 June 2026. Owens. Tech Times. ↩
-
The Secret Token Underworld. 29 June 2026. The PrimeTime. ↩