The Mug Club Archivist

Recently, the show Louder with Crowder moved from BlazeTV to Rumble/Locals. Their previous library of episodes does not appeared to have moved with them, preserved only on BlazeTV’s website in an archive section. People like to believe things put on the Internet stick around forever. If you were on-line during the early years, you’ve probably realized how much of the old Internet has disappeared. I never asked for a BlazeTV membership when I joined Mug Club, so I figured this would be a good time to archive the show. Using a little bit of web development knowledge and Python, I created a snapshot of a show that changed the landscape of conservative political satire and comedy in the late 2010s.
Digging Around
I tend to use yt-dlp as a Swiss Army Knife for archiving videos from around the Internet. It doesn’t support BlazeTV directly, but using the web debugging console, it is possible to dig around in the requests to find the relevant HTTP Live Stream (HLS) requests.
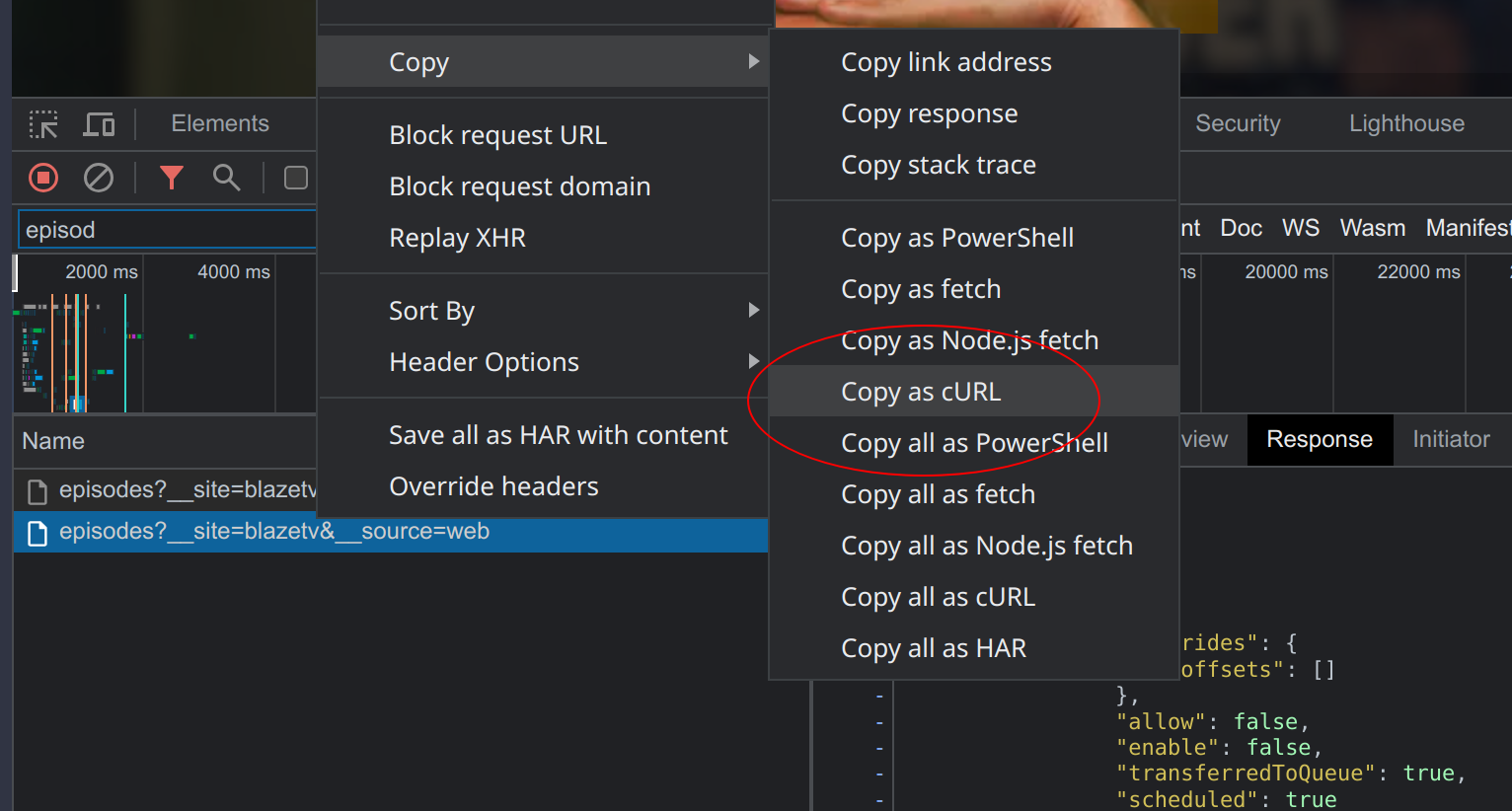
One thing that’s super helpful is the ability to copy individual web requests as curl commands. This makes it easy to examine JSON data directly in a terminal, or redirect it out to a file. All relevant headers are included to make the request look similar to the request made from the browser:
curl 'https://ga-prod-api.powr.tv/v2/sites/blazetv/series/1RBcFcMd5N0w-louder-with-crowder-latest-episodes/episodes?__site=blazetv&__source=web' \ -H 'authority: ga-prod-api.powr.tv' \ -H 'accept: application/json, text/plain, */*' \ -H 'accept-language: en-US,en;q=0.5' \ -H 'authorization: Bearer ***removed***' \ -H 'origin: https://www.blazetv.com' \ -H 'referer: https://www.blazetv.com/' \ -H 'sec-fetch-dest: empty' \ -H 'sec-fetch-mode: cors' \ -H 'sec-fetch-site: cross-site' \ -H 'sec-gpc: 1' \ -H 'user-agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36' \ --compressed
In the above command, I’ve removed the bearer authorization token. With a logged in token, this will output a JSON representation of all the episodes in the Louder with Crowder archive. There’s an incredible amount of metadata for each episode. The following is just a small snippet of a single record:
...
"channels": [
"SERIES",
"SHOWS_SERIES",
"SERIES",
"LWC-CDN"
],
"products": [],
"rentals": [],
"sites": [
"blazetv",
"blazetv-louderwithcrowder",
"blazetv-producer",
"blazetest"
],
"status": "public",
"type": "episode",
"_id": {
"uid": "2b9fd779-85cf-44b3-aeeb-0951a7bc3e8e",
"source": "fuel-test-cdn"
},
"title": "Crowder’s 2022 Midterm Election Livestream Part 1",
"freeToWatch": false,
"uid": "79-a4fixk4uduzv-2022-11-09-louder-with-crowder-1-clipped",
"description": "Steven Crowder and the LWC team bring you LIVE coverage of the 2022 midterm elections with a star-studded cast of guests.",
"createdAt": "2022-11-09T06:10:24.104Z",
"rating": 400,
"ageGate": null,
"badge": {
"blazetv-louderwithcrowder": null,
"blazetv": null
},
...
There isn’t enough information here to begin downloading an episode. An additional request needs to be made to and endpoint called play-url with the uid listed in the metadata. This will give us the actual m3u8 playlist needed to download the video. The authorization token is very short lived. It can be found via the network console by looking for its header.
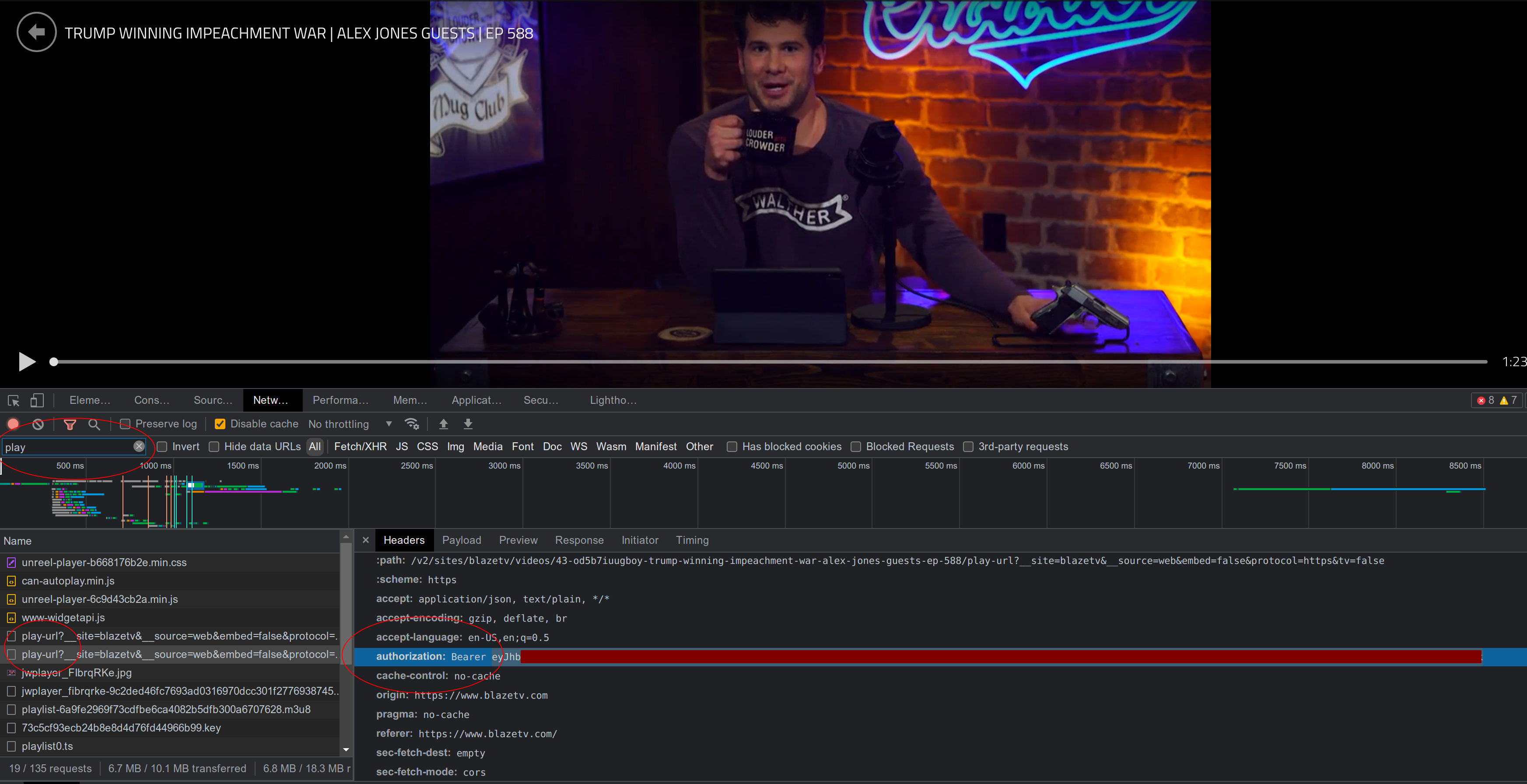
This token is only good for a few minutes. There is likely another endpoint where the session cookie can be used to get a new token, similar to the second version of the Docker registry protocol1. However, rather than reverse engineer how that works and implement the flow in Python, I made sure the script saved its metadata whenever the authorization failed. This way I could grab a new token from the browser and run the command multiple times to pull all the needed playlists.
In the following scrape.py script, the auth token will have to be set. The output from the /episodes request made via curl above is expected to be in a file named episode-data.json. The script will create a output named playlists.json. You may need to run this script multiple times if the authorization token expires.
#!/usr/bin/env python3
import json
import requests
import sys
import logging
import os
log = logging.getLogger('scrape')
logging.basicConfig(format='%(asctime)s %(message)s')
log.setLevel(logging.DEBUG)
auth = '<insert auth token>'
def get_playlist_url(id, bearer_token):
headers = {'authority': 'ga-prod-api.powr.tv',
'accept': 'application/json, text/plain, */*',
'accept-language': 'en-US,en;q=0.5',
'authorization': f'Bearer {bearer_token}',
'cache-control': 'no-cache',
'origin': 'https://www.blazetv.com',
'pragma': 'no-cache',
'referer': 'https://www.blazetv.com/',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'cross-site',
'sec-gpc': '1',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
url = f'https://ga-prod-api.powr.tv/v2/sites/blazetv/videos/{id}/play-url?__site=blazetv&__source=web&embed=false&protocol=https&tv=false'
resp = requests.get(url, headers=headers)
return resp.json()['url'] if 'url' in resp.json() else None
def load_episode_data():
with open("episode-data.json", "r") as raw_data:
return json.load(raw_data)
def load_playlist_data():
if not os.path.isfile("playlists.json"):
return []
with open("playlists.json", "r") as fd:
return json.load(fd)
def save_playlist_data(metadata):
with open("playlists.json", "w") as n_fd:
json.dump(metadata, n_fd)
def build_metadata(episode_list, playlist_data, bearer_token):
existing_titles = [p['title'] for p in playlist_data]
for season in episode_list:
for episode in season:
if episode:
title = episode['title']
if title in existing_titles:
log.debug(f'Already have playlist for {title}. Skipping...')
continue
episode_uid = episode['uid']
publish_date = episode['metadata']['publishedDate']
season_no = episode['series']['season']
episode_no = episode['series']['episode']
playlist_url = get_playlist_url(episode_uid, bearer_token)
if not playlist_url:
log.error("Auth Token Expired")
return playlist_data
episode_info = {
"title": title,
"episode_uid": episode_uid,
"publish_date": publish_date,
"season_no": season_no,
"episode_no": episode_no,
"playlist_url": playlist_url
}
log.debug(episode_info)
playlist_data.append(episode_info)
return playlist_data
episode_data = load_episode_data()
playlist_data = load_playlist_data()
updated_playlist = build_metadata(episode_data, playlist_data, auth)
log.info(f"Previous playlist data records {len(playlist_data)}")
log.info(f"Current playlist data records {len(updated_playlist)}")
log.info("Saving Playlist Data")
save_playlist_data(updated_playlist)
The resulting playlists.json is a subset of the total video metadata that can be used to download and properly name vidoes.
...
{
"title": "Am I Leaving YouTube? ... | Ep 552",
"episode_uid": "43-axfvdc9vqtwu-am-i-leaving-youtube-ep-552",
"publish_date": "2019-09-26T02:06:00.000Z",
"season_no": 4,
"episode_no": 55,
"playlist_url": "https://streamshls.unreel.me/smedia/xxxx/af/yyyy/jwplayer_1234.m3u8"
},
{
"title": "Dear Guru Crowder: I'm a Man Who Likes Lady Clothes... | Ep 550",
"episode_uid": "43-dqm4lpero098-dear-guru-crowder-im-a-man-who-likes-lady-clothes-ep-550",
"publish_date": "2019-09-23T23:33:00.000Z",
"season_no": 4,
"episode_no": 57,
"playlist_url": "https://streamshls.unreel.me/smedia/aaaa/ww/tttt/jwplayer_5678.m3u8"
},
...
For the actual downloads, I use the trusted yt-dlp program, and call it directly from Python in order to archive the videos2. The playlist URLs with the m3u8 extensions appear to be served from a 3rd party provider and do not require authentication. The following download.py script will be expecting a videos directory to exist, where it will archive each episode sequentially.
import json
import logging
import yt_dlp
import os
log = logging.getLogger('download')
logging.basicConfig(format='%(asctime)s %(message)s')
log.setLevel(logging.DEBUG)
def download_video(filename, playlist_link):
if os.path.isfile(filename):
log.info(f"{filename} exists. Skipping...")
else:
opts = {
'outtmpl': filename
}
with yt_dlp.YoutubeDL(opts) as ydl:
ydl.download([playlist_link])
def load_playlist_data():
with open("playlists.json", "r") as fd:
return json.load(fd)
def normalize_filename(episode_data):
date = episode_data['publish_date'].split("T")[0]
title = episode_data['title'].replace("|", "-").replace("/", "-")
return f"videos/[{date}] {title}.mp4"
playlist_data = load_playlist_data()
playlist_data.reverse()
for p in playlist_data:
filename = normalize_filename(p)
log.info(f"Processing {filename}")
download_video(filename, p['playlist_url'])
The Importance of Archival
The entire process took several days and consumed over 1TB of storage space. I could have split the list and archived videos in parallel, but I wasn’t in a hurry. In the code above, the playlist_data list was reversed so I could pull and watch the oldest videos first as I was downloading them. I only started paying attention to Steven Crowder around 2021. Looking into a time capsule from only a few years ago, before I kept up with the show, is a pretty fascinating experience.
I originally kept the season and episode data in the playlists.json to be used for file naming. However, the season numbers didn’t seem consistent, and I ended up just naming each episode by its title, prefixed by the date. I also replaced all | with : in the episode titles, as the bar can be problematic in filenames as it’s also the pipe operator in most shells. After I started the archival process, I discovered some titles also had / characters, creating new sub-directories. I renamed them to use - instead and added another replacement to the script, but a cleaner approach in Python would be to use os.path.join() instead.
It’s important to keep around the original episode-data.json with the archive, as it has a lot of information and internal tags that can be useful in the future. For example, the BANNED ON YOUTUBE tag to indicate which videos were censored by Google/YouTube.
The show always marked their crowd funded member’s program as Mug Club. When I initially subscribed, I didn’t realize it was essentially a BlazeTV membership. Although I am looking forward to Dave Landau’s upcoming show3, I do not care enough to continue with their streaming service.
This post was less of a instruction manual, and more as a general idea book for developers. Most of the above examples are missing details that require experience with web and Python development to use. They also require a current BlazeTV subscription. This isn’t about pirating content, so much as preserving a snapshot in time. The code is somewhat messy, and was kept as simple as possible. Archival scripts are often tailored for specific systems, and tend to get thrown away after their purpose has been served.
I currently still subscribe to the new version of Mug Club hosted on the Locals platform owned by Rumble. I do think Crowder is still a significant and relevant force against the legacy media. However, he has faced a considerable amount of controversy over some recent leaks and some of his actions. In a future post, I may cover some of my thoughts on Steven Crowder, in the context of the new media landscape.
-
Retrieve Docker image tags from a 3rd party repo. 9 May 2019. djsumdog. Stackoverflow. ↩
-
How to use youtube-dl from a python program?. 5 August 2013. Stackoverflow. ↩
-
“YOUR WELCOME” with Michael Malice #255: Dave Landau. 20 April 2023. Michael Malice. ↩