ZFS Woes, or how ZFS Saved Me From Data Corruption
I’ve been using ZFS for years on my Linux storage server. Recently I upgraded from Alpine 3.12 to 3.14, which included a ZFS 0.8 to ZFS 2.0 update. Not soon after, I started getting random file corruption issues. I didn’t see any SMART errors on the drives, but still assumed that my hard drive could be going bad. My storage had outgrown my previous backup drive anyway, so I purchased an additional drive. When I attempted to sync snapshots to the new device, I started to see I/O errors and kernel panics. I took a long journey through ZFS bug reports, attempted to switch to Btrfs and even migrated my storage to a different computer. In the end, ZFS saved me from what could have been disastrous amounts of data corruption due to faulty hardware.
The first noticeable problems involved videos cutting off midstream, following by I/O errors. When I ran zpool status -v on my file server, I saw irrecoverable errors:
pool: claire
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A
scan: scrub canceled on Sun Oct 31 12:58:31 2021
config:
NAME STATE READ WRITE CKSUM
claire ONLINE 0 0 0
sdf1 ONLINE 0 0 0
errors: Permanent errors have been detected in the following files:
claire/storage:/seedbox/sync/KONOSUBA - God's blessing on this wonderful world! S01 Hybrid Remux/KONOSUBA - God's blessing on this wonderful world! S01E03 2016 1080p Bluray Hybrid-REMUX AVC LPCM 2.0 Dual Audio -ZR-.mkv
claire/storage:/blockchains/bitcoin/blocks/blk00032.dat
claire/storage:/tv/The Norm Show/season_2/the.norm.show.202.dvdrip.xvid-ositv.avi
claire/storage:/tv/The Norm Show/season_2/the.norm.show.206.dvdrip.xvid-ositv.avi
claire/storage:/seedbox/sync/KONOSUBA - God's blessing on this wonderful world! S01 Hybrid Remux/KONOSUBA - God's blessing on this wonderful world! S01E04 2016 1080p Bluray Hybrid-REMUX AVC LPCM 2.0 Dual Audio -ZR-.mkv
claire/storage:/seedbox/sync/KONOSUBA - God's blessing on this wonderful world! S01 Hybrid Remux/KONOSUBA - God's blessing on this wonderful world! S01E08 2016 1080p Bluray Hybrid-REMUX AVC LPCM 2.0 Dual Audio -ZR-.mkv
claire/storage:/seedbox/sync/KONOSUBA - God's blessing on this wonderful world! S01 Hybrid Remux/KONOSUBA - God's blessing on this wonderful world! S01E09 2016 1080p Bluray Hybrid-REMUX AVC LPCM 2.0 Dual Audio -ZR-.mkv
claire/storage:/video_production/final_production/DNC-Milwukee-master.mov
...
...
...
I attempted to create a new snapshot of the current state of the disk and use zfs send to save it to the new hard drive. This led to kernel panics and freezes. I decided instead to load my most recent complete snapshot as read-only, use zfs send to sync that snapshot to the new volume, and then use rsync to copy the rest (noting which files were irrecoverable/lost due to I/O errors). Even using rsync led to kernel panics, and full system freezes requiring reboots.
[115447.377386] general protection fault, probably for non-canonical address 0xfbff9113dd743860: 0000 [#1] SMP NOPTI [115447.378271] CPU: 1 PID: 15658 Comm: kworker/u64:11 Tainted: P O 5.10.61-0-lts #1-Alpine [115447.378744] Hardware name: System manufacturer System Product Name/PRIME A320I-K, BIOS 2202 07/14/2020 [115447.379231] Workqueue: writeback wb_workfn (flush-zfs-3) [115447.379726] RIP: 0010:locked_inode_to_wb_and_lock_list+0x1a/0x150 [115447.380231] Code: 00 e9 47 ff ff ff 66 2e 0f 1f 84 00 00 00 00 00 0f 1f 44 00 00 41 54 55 48 8d af 88 00 00 00 53 48 89 fb 4c 8b a3 f8 00 00 00 <49> 8b 04 24 48 83 c0 60 49 39 c4 74 19 49 8b 84 24 00 02 00 00 a8 [115447.381289] RSP: 0018:ffffb61300323c38 EFLAGS: 00010246 [115447.381829] RAX: 0000000000000000 RBX: ffff911668b4dbd8 RCX: 0000000000003000 [115447.382387] RDX: 0000000000000001 RSI: ffffffffffffffff RDI: ffff911668b4dbd8 [115447.382944] RBP: ffff911668b4dc60 R08: 0000000000000000 R09: 0000000000000000 [115447.383444] R10: ffffffffffffffff R11: 0000000000000018 R12: fbff9113dd743860 [115447.383879] R13: ffff9113dd743860 R14: ffff911668b4dbd8 R15: ffffb61300323e20 [115447.384308] FS: 0000000000000000(0000) GS:ffff9116d0840000(0000) knlGS:0000000000000000 [115447.384743] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [115447.385157] CR2: 00007f8f1fa91430 CR3: 0000000254e54000 CR4: 00000000003506e0 [115447.385582] Call Trace: [115447.386005] writeback_sb_inodes+0x235/0x430 [115447.386433] __writeback_inodes_wb+0x4c/0xd0 [115447.386857] wb_writeback+0x1d3/0x290 [115447.387279] wb_workfn+0x292/0x4d0 [115447.387706] ? __switch_to_asm+0x42/0x70 [115447.388137] process_one_work+0x1b1/0x350 [115447.388565] worker_thread+0x50/0x3b0 [115447.388991] ? rescuer_thread+0x380/0x380 [115447.389421] kthread+0x11b/0x140 [115447.389847] ? __kthread_bind_mask+0x60/0x60 [115447.390279] ret_from_fork+0x22/0x30 ... ...
In searching for potential ZFS issues, I came across a bug report about data corruption on various Linux distributions when upgrading to ZFS for Linux 2.01. While searching for the error messages I received, I discovered forum threads where some users questioned ZFS 2.x stability, while many others claimed they had been using it without issue2. At this point, I was wondering if I had stumbled into a ZFS 2.0 bug. I then formatted the new drive I had purchased with Btrfs (on top of LUKS for encryption). Although I haven’t used Btrfs in a long time, I remember it being stable as a root filesystem on my primary workstation years ago. The only issue I remember was free space not clearing up after deleting files, unless I forced a rebalance. There seem to be some outstanding RAID issues as well, but in this case, I’m just using a single disk.
During the rsync process, there were two instances where an I/O error would lock the destination Btrfs disk as read-only.
storage/PhotosX/DONE/2015.06.02/DSC02680.JPG storage/PhotosX/DONE/2015.06.02/DSC02681.JPG rsync: [receiver] write failed on "/mnt/krissy/storage/PhotosX/DONE/2015.06.02/DSC02681.JPG": Read-only file system (30) rsync error: error in file IO (code 11) at receiver.c(378) [receiver=3.2.3] rsync: [sender] write error: Broken pipe (32)
This I/O error would be complemented with an error in the Linux kernel log.
[44114.290330] BTRFS: device label krissy devid 1 transid 5 /dev/mapper/sdf1_crypt scanned by mkfs.btrfs (30428) [44161.998360] BTRFS info (device dm-3): disk space caching is enabled [44161.998363] BTRFS info (device dm-3): has skinny extents [44161.998364] BTRFS info (device dm-3): flagging fs with big metadata feature [44162.000191] BTRFS info (device dm-3): checking UUID tree [51941.219234] BTRFS critical (device dm-3): corrupt leaf: root=256 block=239960064 slot=0 ino=50121, invalid location key offset:has 64 expect 0 [51941.219238] BTRFS info (device dm-3): leaf 239960064 gen 249 total ptrs 156 free space 3 owner 256 [51941.219240] item 0 key (50121 96 25) itemoff 16238 itemsize 45 [51941.219241] item 1 key (50121 96 26) itemoff 16198 itemsize 40 [51941.219241] item 2 key (50121 96 27) itemoff 16158 itemsize 40 [51941.219242] item 3 key (50122 1 0) itemoff 15998 itemsize 160 [51941.219243] inode generation 228 size 0 mode 40700 [51941.219243] item 4 key (50122 12 50081) itemoff 15970 itemsize 28 [51941.219244] item 5 key (50123 1 0) itemoff 15810 itemsize 160 [51941.219245] inode generation 228 size 0 mode 40700 [51941.219245] item 6 key (50123 12 50081) itemoff 15792 itemsize 18 [51941.219246] item 7 key (50124 1 0) itemoff 15632 itemsize 160 ... ... [51941.221863] item 122 key (50121 96 23) itemoff 10182 itemsize 43 [51941.221864] item 123 key (50121 96 24) itemoff 10136 itemsize 46 [51941.221864] BTRFS error (device dm-3): block=411910144 write time tree block corruption detected [51941.264708] BTRFS: error (device dm-3) in btrfs_commit_transaction:2389: errno=-5 IO failure (Error while writing out transaction) [51941.264713] BTRFS info (device dm-3): forced readonly [51941.264716] BTRFS warning (device dm-3): Skipping commit of aborted transaction. [51941.264719] BTRFS: error (device dm-3) in cleanup_transaction:1944: errno=-5 IO failure
Twice I unmounted the drive, and ran btrfsck on the disk. No errors were reported, and I was able to continue the rsync. I assumed there may have been some issues with Btrfs failing safely to a read-only state when ZFS started throwing errors. After I synchronized my most recent ZFS snapshot and what I could of newer data, I decided to run sha256sum on all the music files in my read-only ZFS backup. I could compare it to the new Btrfs volume, to check the data integrity. However, on the brand new Btrfs volume, I started to see I/O errors, and using the Btrfs tools for scrubbing showed several corrupt files.
sha256sum: can't read 'Music/music_cds/Wendy's Yellow Poncho - Glass Beach/Wendy's Yellow Poncho - Glass Beach - 03 Sea to Sea.flac': I/O error sha256sum: can't read 'Music/music_cds/Young Heirlooms - Young Heirlooms/Young Heirlooms - Young Heirlooms - 04 Never Truly Dear.flac': I/O error
At this point, I suspected something was seriously wrong with the storage server itself. I pulled the side panels off my primary development machine and attached my storage drives. My primary development box runs Gentoo and had ZFS 2.1.1 available in its package tree. I decided to delete the Btrfs volume and go back to ZFS. I, once again, used zfs send and zfs recv to sync the most recent good snapshot. There were no kernel panics. I then used rsync to update any files since the last snapshot. I redirected stderr to a second file to keep track of which files had errors. Finally, after the new drive was up to date, I ran zfs scrub on the volume. During this entire time, I kept the kernel log open with dmesg -w. The scrub finished with zero errors reports, and there were no kernel errors.

So What Happened?
There were several changes that happened in a short amount of time. Any of them could have been the culprit.
- Upgrading from Alpine 3.12 -> 3.14 could have introduced some kernel issue relating to block devices
- Updating ZFS 0.8 to 2.0.1 (as part of the Alpine upgrade) could have introduced a filesystem bug (unlikely since this affected Btrfs as well)
- The SATA PCI-E card might have been going bad and silently allowing errors
- The memory, processor or other piece of hardware may have been failing
I started off with memory by running memtest86 from a bootable USB stick.
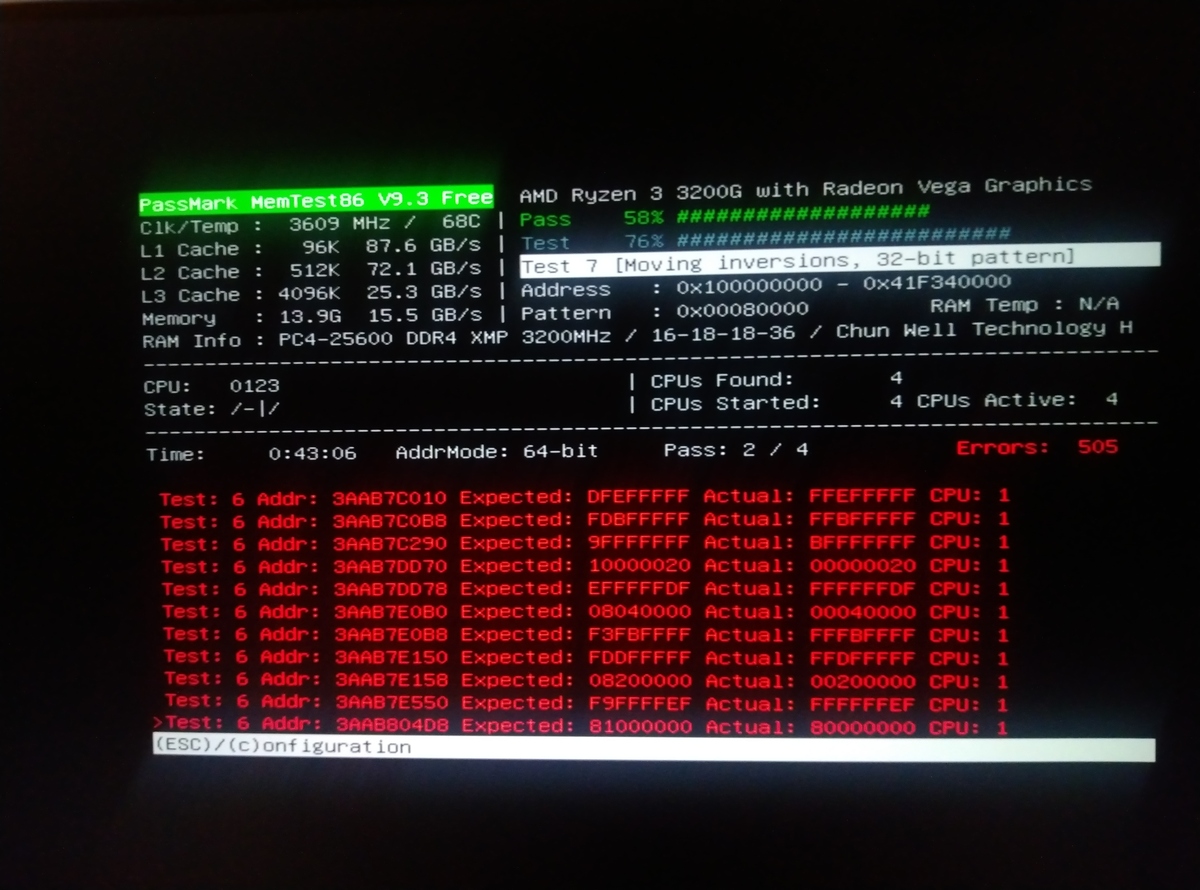
Well, there was the issue. The 16GB of OLOy DDR4 memory in this system was going bad. I originally purchased this memory in September of last year. OLOy required memetest86 photos to process a warranty. After e-mailing them the one above, I got an RMA number and an American address to ship the memory to. I replaced the bad RAM with a 16GB spare I had leftover from my gaming system upgrade, and ran memtest86 again to ensure it was in good condition.

Going Forward
Unfortunately, the motherboard in my file server doesn’t support error correcting (ECC) memory. For now, I’ll use more frequent backups to minimize data loss, and possibly look for boards that support ECC memory for future upgrades. I’ll also need to replace the operating system on this server, since packages have been installed and upgraded while I was using bad memory modules (and could potentially be corrupt). I could simply reinstall all the Alpine packages, but I decided this would be a good time to look at FreeBSD.
My storage server was very minimal, only running NFS and Samba. There was nothing wrong with Alpine; it was minimal and ran well. Yet, when I originally posted my video on my storage server build, I did get questions about why I had gone with ZFS on Linux instead of FreeBSD. I do like having different operating systems and distributions running on my home network, so I can get familiar and comfortable with all of them. I was also curious about interoperability, and how my disks would behave on FreeBSD 13.
I installed FreeBSD on my storage server and loaded up one of my secondary storage volumes. I crated and synced a snapshot to its backup volume, and preformed a scrub on it while monitoring the kernel log. Everything worked as expected with zero errors.
# zpool status -v
pool: clarissa
state: ONLINE
scan: scrub repaired 0B in 11:51:51 with 0 errors on Sat Nov 6 10:02:03 2021
config:
NAME STATE READ WRITE CKSUM
clarissa ONLINE 0 0 0
da0p1 ONLINE 0 0 0
errors: No known data errors
ZFS on Linux 2 and FreeBSD 13’s ZFS implementation seem interoperable. When first attempting zpool import after moving to a new system, I did get the following notice, indicating I needed to import the pool with the -f flag.
cannot import 'krissy': pool was previously in use from another system. Last accessed by <unknown> (hostid=0) at Sun Nov 7 03:32:00 2021 The pool can be imported, use 'zpool import -f' to import the pool.
I migrated primary storage back over to FreeBSD, created a snapshot, and ensured my primary backup was also up to date. I monitored kernel logs in FreeBSD and scrubbed the backup volume to ensure there were no disk errors. Although the device names look a bit different in FreeBSD, all the ZFS commands are identical with the exact same output and status messages. The tooling was completely familiar, even on a different operating system. I now have all my storage back online, with all of my important volumes backed up via ZFS snapshots, and the backup volumes removed from the server and safely offline.

Conclusions
Many of the operations I described took a long time. Syncing 14TB of data over a SATA III interface will easily run overnight. Getting my data pools back in order was a stressful ordeal, that often involved a lot of waiting. ZFS, with its builtin file integrity checks and scrubbing, helped me see and identify data integrity issues very early on. Using ZFS snapshots, in conjunction with zfs set readonly=on before reading backup volumes, provided an easy and safe means to pull a new physical drive back up to a known good state.
There were a lot of red hearings while going down the path of diagnosing what had gone wrong. Although I had initially considered faulty hardware, I had stopped at the hard drive. Continued issued led me to question if there was a software issue, brought on by my recent Alpine (and thereby ZFS) upgrades. Reports from end-users on ZFS 2 led me further down this path, instead of looking more closely at hardware first. Switching filesystems and getting the same errors, finally led me to attaching the physical drives to a different system. This also opened opportunities to diagnose the original server.
Despite what seems like pretty serious memory issues, I only lost 56 files total. Some of these files were temporary data I could discard. Others I could restore from other backups, or simply download again. Although I will look to replacing my storage server with one that uses ECC memory in the future, I do plan to continue to use ZFS for it’s amazing snapshot and data integrity features.
-
ZFS corruption related to snapshots post-2.0.x upgrade #12014. 8 May 2021. Retrieved 6 November 2021. openzfs. Github. ↩
-
Is it just an illusion, or Zfs 2.* is just too buggy?. 18 May 2021. u/Boris. Reddit. ↩