Nearly a decade ago, I was purchasing beer for a friend’s party at a drug store and the cashier wanted to scan my drivers license. I refused and her manager said my ID had to be scanned to make my purchase. The cashier was surprised no one had refused a scan before. Sometimes people have scanned my IDs before I could stop them, so I put a sticker on the back of my drivers license. Increasingly, more businesses and restaurants are demanding this invasive tracing of customers for entry or alcohol purchase. No matter how much a bouncer may claim “we don’t store your information,” they have literally no way of being sure of that. If you value your privacy, do not let venues or stores scan your drivers license.
When Elon Musk originally bought Twitter, a number of people moved over to Mastodon. There were a lot of misunderstandings around how Mastodon works. People are used to mega-websites, now known as platforms. Mastodon is composed of tens of thousands of independently run servers that communicate with each other using a protocol known as ActivityPub (AP). There are other services that can communicate over AP, including Pleroma, PeerTube, Misskey, PixelFed and more. This interconnected network is colloquially known as The Fediverse. People use to the mega-sites and large-scale algorithmic content moderation were completely unprepared for a return to distributed, chronological, non-algorithmic social networking.
I’ve been using Stack Overflow, and other Stack Exchange sites, for over fourteen years. During that time, I’ve both asked and answered over 80 questions, with some overlap of providing answers to my own queries. Even when I was younger, I limited my questions to things that were truly difficult problems I was stuck on. The site has provided some great insights and has helped me tackle difficult coding issues. Recently, the amount of questions submitted has gone into massive decline. A few weeks ago, I used the site to ask questions about a very difficult problem I was facing, which involved Python and Qt using PyQt bindings. The comments I got were condescending. Even as I provided more information and fully reproducible examples, I was told to further condense my questions before they were eventually closed and deleted. Stack Overflow is no longer the website I once enjoyed using.
A few years ago, I built out a home theater system, after not having a TV for nearly a decade. Even after leaving my life of minimalism, I still just watched movies and shows on a regular desktop monitor or laptop. I was surprised at how difficult it was to get HDR support working on Linux, and how limited my options were. For years, I simply used Windows 10 and the VLC media player to play videos with HDR and high quality audio. Although true HDR is now possible on Linux, it’s still not entirely straightforward and took a little bit of work. This guide explains how to setup mpv media player with HDR on KDE Neon Linux, but should be adaptable to other Wayland based setups.
Years ago, I donated most of the physical books I had to local libraries in preparation for moving out of the country. While abroad, I switched to reading books on a tablet device as a way of staying minimalistic. In the fall of 2021, I purchased my first e-ink reader: A Kobo Mini. Although it was new old stock, the reader was already past its support life when I purchased it. I’ve read over a dozen books on it in the past three years, but this small e-reader is starting to show its age. Momentarily, I tried an Amazon Kindle, which turned out to be a horrible mistake.
I ended up replacing the Kobo Mini with a PocketBook Verse Pro Color. It had to be ordered from Europe since it’s not available in American markets. It’s a great little reader, and I’ve already finished six books on the device in the first two months I’ve had it. In this post I’ll go over the Kobo, the issues I ran into with Amazon products, and my current thoughts on the PocketBook.
I like to keep backups of things other people just leave “in the cloud,” (which is really just some private corporation’s computer). In the past, I’ve used eReader software on tablets or phones. I wanted to create a book quote bot that would post random highlights from novels I’ve read. In order to do so, I first had to write tools to convert book highlights into usable formats. Bibliobunny is a Python application I wrote to parse notes from Amazon Kindle and Google Play note formats into JSON. It can also load those JSON files into a sqlite database, which can be used to post book quotes to a Pleroma server.
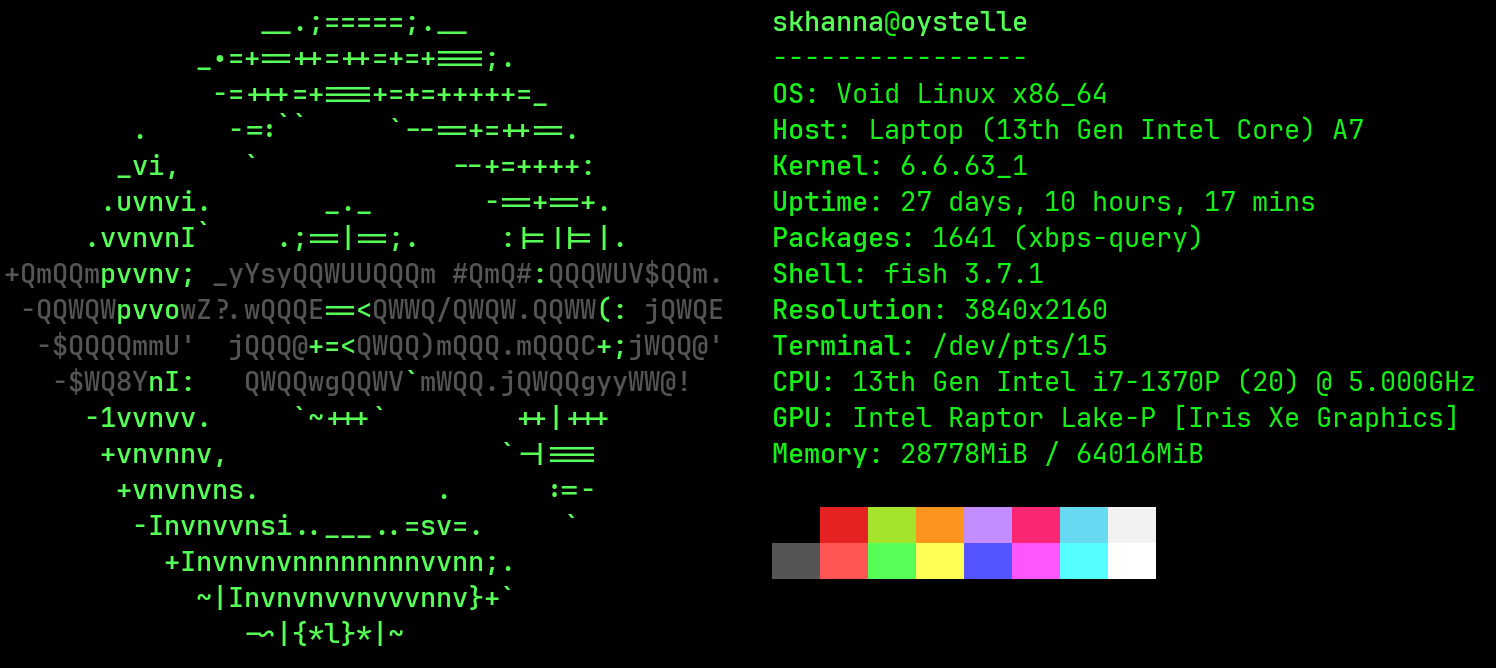
I’ve been using Void Linux on several of my servers and my work laptop. I’ve found it to be a stable Linux distribution, with many of the tools I commonly use in its package repository. It is not derived off of another distribution, and is built around its own xbps package manager. Some of the commands for xbps are a bit difficult to remember, and it doesn’t have the best command line interface. Void also uses runit for service management, which also has some non-traditional ways of handling services. In this article, I’ll go over some valuable tools, such as vpm and vsv, which greatly improve the Void Linux command line experience. I’ll also go over voidup, a tool I built for creating custom package repositories on Void Linux.
I’ve had my current phone since 2019. I’ve gone through a lot of mobile devices over my life, and it’s been nice to have a single phone that’s lasted this long. Although most of the phone seems to work fine, the LTE connectivity issues I had to deal with previously have only gotten worse. Phone calls, both over my normal carrier and via jmp.chat have been incredibly unreliable for over a year. I suspect that some of the hardware (possibly the cell modem and the microphone) has physically degraded. So after nearly five years, I got a new device. I’ll go over the steps I take to de-Google my device, as well as some of my favorite mobile applications, both open source and proprietary.
The Network Neighborhood icon, appearing in Windows 95 and NT4, allowed people to share files between computers connected on a home network. At universities and LAN parties, people used to make copies of the videos they watched, long before the growth of large video sharing websites. YouTube did so well during the video hosting wars that it was purchased by Google. Being a massive monolith of a video sharing website, it’s also rife with censorship. I archive videos that I find interesting, which are also at high risk of disappearing. I wrote a program called Youboot to scan my collection of downloaded videos, and tell me which ones are no longer available and the reason they were removed. The best offense, in the war against thought-crime, is to watch the videos the powerful want to burn.